



Neben diesen allgemeinen Entwurfseigenschaften sind bei der DBS-Realisierung, wie erwähnt, eine Reihe zusätzlicher Anforderungen einzuhalten, die eine effiziente und zuverlässige Systemnutzung gewährleisten sollen. Bei diesen Nebenbedingungen wollen wir zwei besonders betonen. Damit ein DBS im praktischen Einsatz akzeptiert wird, muß es die angebotenen Operationen ausreichend effizient ausführen können.[5] Dazu hat es einen Vorrat an geeigneten Speicherungsstrukturen und Zugriffspfaden sowie spezielle, darauf zugeschnittene Verfahren der Anfrageoptimierung bereitzuhalten. Neben dem Leistungsaspekt gilt ein hoher Grad an Datenunabhängigkeit als wichtigste Nebenbedingung des Systementwurfs. Datenunabhängigkeit soll einerseits eine möglichst große Isolation von Anwendungsprogramm und DBS gewährleisten und andererseits auch innerhalb des DBS eine möglichst starke Kapselung der einzelnen Komponenten bewerkstelligen. Datenunabhängigkeit muß deshalb durch eine geeignete DBS-Architektur unterstützt werden.
Da beim Einsatz von DBS bei der Vielfalt kommerzieller Anwendungen eine große Variationsbreite und Änderungswahrscheinlichkeit in der Darstellung und Menge der gespeicherten Daten, in der Häufigkeit und Art der Zugriffe sowie in der Verwendung von Speicherungsstrukturen und Gerätetypen zu erwarten ist, muß beim Systementwurf Vorsorge dafür getroffen werden. Erweiterbarkeit und Anpaßbarkeit sind beispielsweise nur zu erreichen, wenn die Auswirkungen von später einzubringenden Änderungen und Ergänzungen in der DBS-Software lokal begrenzt werden können. Diese Forderungen lassen sich am besten durch eine DBS-Architektur realisieren, die sich durch mehrere hierarchisch angeordnete Systemschichten auszeichnet. Aus diesem Grund verwenden wir hier als methodischen Ansatz ein hierarchisches Schichtenmodell zur Beschreibung des Systemaufbaus. Durch die einzelnen Abbildungen (Schichten) werden die wesentlichen Abstraktionsschritte von der Externspeicherebene bis zur Benutzerschnittstelle charakterisiert, die das DBS dynamisch vorzunehmen hat, um aus einer auf Magnetplatten gespeicherten Bitfolge abstrakte Objekte an der Benutzerschnittstelle abzuleiten.
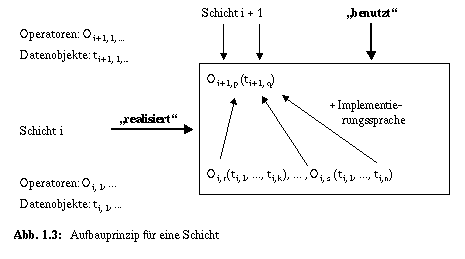
Nach Parnas ergeben sich unmittelbar eine Reihe von Vorteilen für die Entwicklung des SW-Systems, die als Konsequenzen der Nutzung hierarchischer Strukturen und durch die Benutzt-Relation erzielte Kapselung angesehen werden können:
- Änderungen auf höheren Ebenen sind ohne Einfluß auf tieferen Ebenen.
- Höhere Ebenen lassen sich abtrennen, tiefere Ebenen bleiben trotzdem funktionsfähig.
- Tiefere Ebenen können getestet werden, bevor die höheren Ebenen lauffähig sind.
Weiterhin läßt sich jede Hierarchieebene als abstrakte oder virtuelle Maschine auffassen. Solche Abstraktionsebenen erlauben, daß
- die abstrakte Maschine der Schicht i wiederum als Basismaschine für die Implementierung der abstrakten Maschine der Schicht i+1 dient.
Eine abstrakte Maschine entsteht aus der Basismaschine durch Abstraktion. Dabei werden einige Eigenschaften der Basismaschine verborgen. Zusätzliche Fähigkeiten werden durch Implementierung höherer Operationen für die abstrakte Maschine bereitgestellt.
Die eingeführten Prinzipien beantworten noch nicht die Frage nach der Anzahl n der Schichten, die eine "optimale" DBS-Architektur aufweisen sollte. Offensichtlich ist die Wahl von n = 1 nicht geeignet, die oben eingeführten Anforderungen zu erfüllen, da die resultierende monolithische Systemstruktur keine Reduktion der Systemkomplexität erzielt (fehlende Aufteilung) und auch keine Kapselung von Aufgaben und Abbildungsvorgängen im DBS-Code erzwingt. Zur Diskussion einer geeigneteren Architektur wollen wir zunächst die Rolle von n, d. h. der Schichtenanzahl, ausloten. Zwei divergierende Einflußfaktoren lassen sich für n > 1 (bis zu einer vernünftigen Obergrenze bis etwa n < 10) ausmachen. Zunächst führt ein größeres n auf eine Reduktion der Komplexität der einzelnen Schichten. Schritthaltend damit werden wegen der Kapselung die Auswirkungen von Systemänderungen und -ergänzungen eingegrenzt. Also wird damit eine Evolution der Systemfunktionalität oder ihre Anpassung an Umgebungsänderungen einfacher und weniger fehleranfällig. Dagegen ist bei steigender Anzahl der Schnittstellen vor allem mit Leistungseinbußen zu rechnen. Die unterstellte strikte Kapselungseigenschaften der Schichten erzwingt bei jedem Schnittstellenübergang eine Parameterprüfung der Operationsaufrufe und einen Datentransport von Schicht zu Schicht mit einer schichtenspezifischen Konversion der Datentypen und Übertragung der angeforderten Granulate. Das impliziert Kopiervorgänge beim Lesen (nach oben) und Propagieren von Änderungen (nach unten). Zudem wird die nichtlokale Fehlerbehandlung schwieriger, da Fehlermeldungen von Schicht zu Schicht (nach oben) gereicht und dabei "schichtenspezifisch erklärt" werden müssen. Wenn nur innerhalb einer Schicht Annahmen über die Operationsausführung getroffen werden können, werden offensichtlich mit der Verkleinerung der Softwareschicht (Abbildung) auch die Optimierungsmaßnahmen und ihre Reichweiten reduziert. Mit diesen Überlegungen als Entwurfsinformation führen wir nun zuerst ein Drei-Schichten-Modell für den statischen DBS-Aufbau ein. Dieses wird später zur besseren Erklärung und Separierung der Realisierungskonzepte und -techniken zu einem Fünf-Schichten-Modell erweitert. Um die oben erwähnte Problematik der Rolle von n zu entschärfen, wird anschließend gezeigt, wie zur Laufzeit, also bei der Abwicklung von DB-Operationen, einige Schichten "wegoptimiert" werden können, um so ein besseres Leistungsverhalten zu gewährleisten.
- optimale Bedienung der darüberliegenden Schicht mit ihren Aufgaben,
- implementierungsunabhängige und möglichst allgemeine Beschreibung der Funktionen jeder Schnittstelle (Ebene).
Für die Zerlegung und für die Wahl der Objekte/Operatoren läßt sich kein Algorithmus angeben. Deshalb muß sich der Entwurf des Schichtenmodells in der Regel auf "Erfahrung" abstützen.
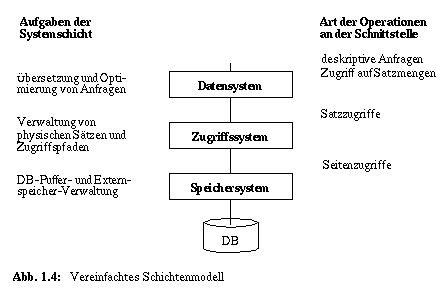
Ein vereinfachtes Schichtenmodell soll zunächst zur Beschreibung der Datenabbildungen von der mengenorientierten DB-Schnittstelle bis zur Externspeicherrepräsentation dienen. Es wurde schon in [ASTR76] zur Darstellung der Architektur eines relationalen DBS in ähnlicher Weise eingeführt. Abb. 1.4 veranschaulicht die Aufgaben der jeweiligen Systemschicht und den Abstraktionsgewinn, den die Operationen auf den jeweiligen Schichten nutzen können. Durch explizite Separierung des Speichersystems heben wir in diesem Modell die Aufgaben der Extern- und Hauptspeicherverwaltung (in Form des DB-Puffers) hervor. So stellt das Speichersystem die Zugriffseinheit "Seite" im DB-Puffer zur Verfügung. Es verbirgt auf diese Weise alle Aspekte der Externspeicherabbildung und -anbindung und bietet somit für höhere Systemschichten die Illusion einer seitenstrukturierten Hauptspeicher-DB. Die Abbildung von Sätzen und Zugriffspfaden auf Seiten erfolgt durch das Zugriffssystem, wobei nach oben ein satzweiser Zugriff auf die physischen Objekte und Speicherungsstrukturen (interne Sätze) angeboten wird. Das Datensystem schließlich überbrückt die Kluft von der mengenorientierten Tupelschnittstelle (für Relationen und Sichten) zur satzweisen Verarbeitung interner Sätze. Dabei ist die Übersetzung und Optimierung von deskriptiven Anfragen eine der Hauptaufgaben dieser Schicht.
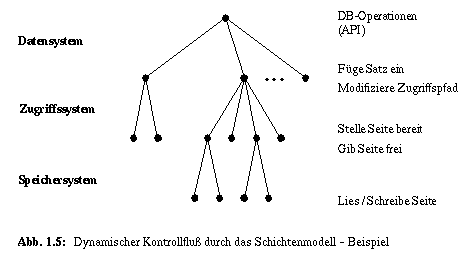
In Abb. 1.5 ist der dynamische Kontrollfluß durch das Schichtenmodell skizziert, um das Zusammenspiel der einzelnen Schichten etwas zu beleuchten. Eine mengenorientierte DB-Operation wird im Datensystem mit Hilfe von satzorientierten Operationen des Zugriffssystems abgewickelt. Manche dieser Operationen können auf bereits im DB-Puffer vorhandenen Seiten ausgeführt werden. Andere Operationen erfordern dagegen das Nachladen (Lesen) oder Ausschreiben von Seiten, was den Aufruf des Speichersystems impliziert. Bei einem sequentiellen DBS kann man sich die Abwicklung des dynamischen Ablaufs nach dem Prinzip der Tiefensuche (left-most, depth-first) vorstellen. Die Ausführung mengenorientierter DB-Operationen erzeugt in vielen Fällen sehr breite Kontrollflußgraphen (oder Mehrwegbäume mit einem großen Verzweigungsgrad, ggf. in allen drei Systemschichten). Deshalb soll Abb. 1.5 auch die Möglichkeit verdeutlichen, daß mengenorientierte DB-Operationen sich neben der Anfrageoptimierung auch zur Parallelisierung eignen. Im Beispiel bedeutet dies, daß bei geeigneten Systemvoraussetzungen mehrere Aufrufe des Zugriffssystems und dort möglicherweise mehrere Aufrufe des Speichersystems parallel abgesetzt und ausgeführt werden können.
Die Datenstrukturen und Operatoren unseres Schichtenmodells sind also generisch, d. h., an jeder Schnittstelle sind nur bestimmte Objekttypen und ihre charakteristischen Operationen vorgegeben, jedoch nicht ihre anwendungsbezogene Spezifikation und Semantik (z. B. durch Angabe spezieller Einschränkungen). Beispielsweise bietet unser Schichtenmodell (Abb. 1.4) an der Schnittstelle des Datensystems nur generische "Relationen" (Satzmengen) mit ihren Operationen. Ihre Anzahl oder ihre konkrete Anwendungsanbindung mit Angabe von Wertebereichen, Attributen, Integritätsbedingungen usw. ist jedoch nicht festgelegt. Ebenso wird die Externspeicherabbildung durch ein generisches Dateikonzept vorgenommen. Die Beschreibung der konkret benötigten Dateien, ihre Anzahl und ihre Verteilung auf Speichermedien sowie andere anwendungsspezifische Parameter sind nicht berücksichtigt.
Diese Beispiele sollen zeigen, daß in jeder Schicht anwendungsbezogene Beschreibungsinformation benötigt wird, um aus dem generischen System ein DBS zu konfigurieren. Diese Beschreibungsinformation wird beim DB-Entwurf gewonnen und z. B. nach dem ANSI/SPARC-Ansatz systematisch geordnet und vervollständigt. Das DB-Schema (mit seiner Unterteilung in externes, konzeptionelles und internes Schema) dokumentiert also den DB-Entwurf und enthält die zugehörige Beschreibungsinformation für ein konkretes DBS in lesbarer Form. Bei der Konfigurierung des DBS muß sie dem System zugänglich gemacht werden, um aus den generischen Objekten konkrete Objekte mit ihren Operationen ableiten zu können. Diese dem DBS zugänglichen Beschreibungsinformationen heißen auch Metadaten. Sie werden zur Laufzeit eines DBS gelesen, interpretiert und ständig aktualisiert. Während der Lebenszeit eines DBS fallen häufig auch sog. Schemaevolutionen an, die Änderungen von Struktur und Beschreibung der Miniwelt im DBS nachvollziehen. Hierbei sind persistente und konsistente Änderungen der Metadaten zu gewährleisten. Deshalb wird eine eigene Metadatenverwaltung bereitgestellt.
Da dafür im Prinzip alle Aufgaben der Datenverwaltung (eine DB zur Beschreibung der DB) durchzuführen sind, entspricht ihre Funktionalität der des eigentlichen DBS. Häufig werden deshalb solche Systeme als eigenständige Systeme entwickelt und am Mark angeboten (Data Dictionary, Data Repository u. a.). In unserer Vorstellung wollen wir jedoch die entsprechende Funktionalität im Rahmen unseres Schichtenmodells beschreiben und integrieren, da dazu prinzipiell dieselben Verfahren und Implementierungstechniken wie für die Verwaltung der eigentlichen DB-Daten erforderlich sind.
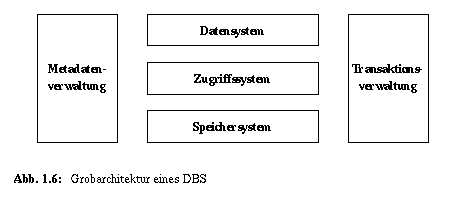
Beschreibungsdaten werden zur Realisierung der Aufgaben in jeder Schicht benötigt. Um dies zu unterstreichen, illustrieren wir in Abb. 1.6 die Metadatenverwaltung als konzeptionell eigenständige Komponente, welche die Abstraktionsebenen aller unserer Modellschichten überdeckt. Das soll nicht bedeuten, daß sie immer auch als eigenständige Komponente realisiert ist. Später werden wir die Beschreibungs- und Abbildungsinformationen wiederum den einzelnen Schichten zuordnen und im Rahmen der Konkretisierung der jeweiligen Schicht beschreiben (siehe Abb. 1.7).
Eine weitere wichtige Aufgabe eines DBS ist die Bereitstellung eines Transaktionskonzeptes (siehe Kapitel 13), was durch die Komponente der Transaktionsverwaltung übernommen wird. Auch hier gibt es verschiedene Möglichkeiten der Realisierung und der Schichtenzuordnung, die erst später detailliert werden können. In Abb. 1.6, in dem nur grobe Zusammenhänge veranschaulicht werden, stellen wir die Transaktionsverwaltung deshalb ebenfalls als schichtenübergreifende Komponente dar.
Jede Systemschicht realisiert die entsprechenden Strukturen der zugeordneten Entwurfsebene. Die Schnittstellen zwischen den einzelnen Schichten werden jeweils durch einige typische Operationen charakterisiert. Die zugehörigen Objekte sind beispielhaft als Adressierungseinheiten für jede Abbildungsschicht dargestellt, wobei die Objekte an der oberen Schnittstelle den Objekten der unteren Schnittstelle der nächsthöheren Schicht entsprechen. Die an einer Schnittstelle verfügbaren Objekte und Operationen werden von den direkt übergeordneten Komponenten wiederum zur Realisierung ihrer spezifischen Strukturen und Funktionen benutzt. Daneben sind noch einige wichtige Hilfsstrukturen und Beschreibungsdaten, die zur Realisierung der Schicht herangezogen werden, angegeben. Das Geheimnisprinzip verlangt, daß diese Hilfsstrukturen an den jeweiligen Schnittstellen nicht sichtbar sind. So lassen sich Änderungen von Implementierungstechniken und (bis zu einem gewissen Grad) ihre Ergänzungen oder Erweiterungen "nach außen" verbergen. Das Geheimnisprinzip ist somit Voraussetzung für die geforderte Anpaßbarkeit und die Erweiterbarkeit des DBS.
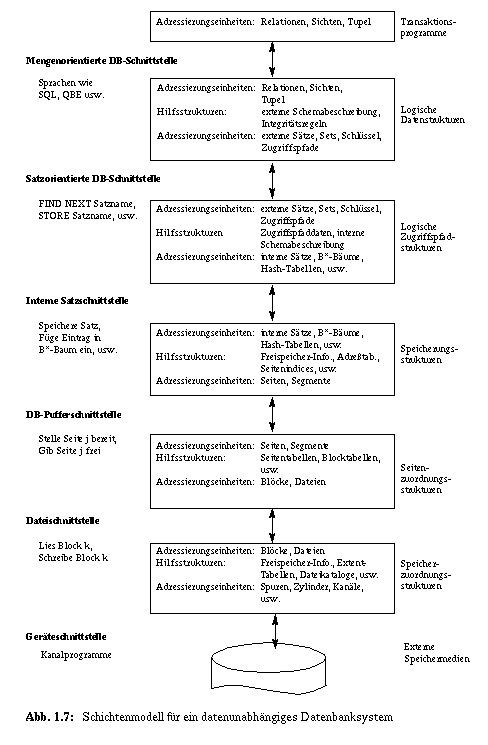
Die Geräteschnittstelle ist durch die verwendeten externen Speichermedien vorgegeben. Durch die Systemschicht, welche die Speicherzuordnungsstrukturen verkörpert, wird eine Dateischnittstelle erzeugt, auf der von Gerätecharakteristika wie Speichertyp, Zylinder- und Spuranzahl, Spurlänge usw. abstrahiert werden kann. Diese explizite Abbildung erzielt eine Trennung von Block und Slot sowie von Datei und Speichermedium.
Die nächste Systemschicht - die Ebene der sog. Seitenzuordnungsstrukturen - realisiert die DB-Pufferschnittstelle und stellt Segmente mit sichtbaren Seitengrenzen als lineare Adreßräume im DB-Puffer zur Verfügung. Dadurch erfolgt eine konzeptionelle Trennung von Segment und Datei sowie Seite und Block. Als Folge davon lassen sich, für höhere Systemschichten verborgen, verschiedenartige Einbringstrategien für geänderte Seiten einführen, die vor allem die Recovery-Funktionen vereinfachen.
Die nächste Systemschicht realisiert eine Menge von Speicherungsstrukturen wie interne Sätze und physische Zugriffspfade, die sie auf Seiten von Segmenten abbildet. Durch ein reichhaltiges Angebot von verschiedenartigen Zugriffspfaden und Speicherungsoptionen, mit denen das Systemverhalten auf die Leistungsanforderungen der konkreten Anwendungen hin optimiert werden kann, trägt diese Systemschicht in besonderer Weise zur Einhaltung von Performance-Zielen bei. Sie implementiert die interne Satzschnittstelle, deren Zweck die Trennung von Sätzen, Einträgen in Zugriffspfaden usw. und Seiten sowie ihrer Zuordnung zu Segmenten ist. Weiterhin erlaubt sie eine Abstraktion von Implementierungsdetails der Sätze und Zugriffspfade.
Die Ebene der Logischen Zugriffspfade stellt eine satzorientierte DB-Schnittstelle zur Verfügung, die eine Bezugnahme auf externe Sätze und auf Funktionen von Zugriffspfaden gestattet. Sie verbirgt die gewählten Implementierungskonzepte für Sätze und Zugriffspfade und erzielt damit eine Unabhängigkeit von den Speicherungsstrukturen. Ihre Funktionsmächtigkeit entspricht der eines zugriffspfadbezogenen Datenmodells. Die satzorientierte DB-Schnittstelle dient in DBS nach dem Hierarchie- oder Netzwerkmodell sowie in objektorientierten DBS (OODBS) als Anwendungsprogrammierschnittstelle. Auch aus diesem Grund wird sie in unserem Schichtenmodell explizit ausgewiesen.
Als oberste Schicht der Abbildungshierarchie wird durch die Ebene der Logischen Datenstrukturen eine mengenorientierte DB-Schnittstelle (zugriffspfadunabhängiges Datenbankmodell) realisiert, die Zugriffsmöglichkeiten in deskriptiven Sprachen bietet. Der Benutzer kommt auf ihr ohne Navigieren auf logischen Zugriffspfaden aus. Neben der Zugriffspfadunabhängigkeit läßt sich auf dieser Schicht mit Hilfe des Sicht-Konzeptes [CHAM80] ein gewisser Grad an logischer Datenstrukturunabhängigkeit erreichen. Ein wichtiges Beispiel für die mengenorientierte DB-Schnittstelle verkörpert das Relationenmodell mit der Sprache SQL.
Während die Systematik der Schichtenbildung sich an den Notwendigkeiten einer geeigneten Objektabbildung orientiert und dadurch in ihrer vorliegenden Form festgelegt ist, ergeben sich für die Einordnung der Datensicherungs- und Recovery-Funktionen eine Reihe von Freiheitsgraden. Zugriffs- und Integritätskontrolle sind jeweils an die an der externen Benutzerschnittstelle (Programmierschnittstelle) sichtbaren Objekte und Operationen gebunden. Deshalb sind die zugehörigen Maßnahmen in der entsprechenden Abbildungsschicht (also entweder in der Schicht der Logischen Datenstrukturen oder in der Schicht der Logischen Zugriffspfade) zu bewerkstelligen. Auch die Transaktionsverwaltung ist einer Schicht zuzuordnen, in der die Zusammengehörigkeit von externen Operationsfolgen eines Benutzer noch erkannt und kontrolliert werden kann. Wie in Kapitel 14 und 15 ausführlich gezeigt wird, können die Synchronisationsverfahren und die Recovery-Funktionen in verschiedenen Abbildungsschichten mit unterschiedlicher Effizienz angesiedelt werden.
In den unteren beiden Schichten bietet ein großer DB-Puffer mit effektiven Verwaltungsalgorithmen die wirksamste Maßnahme zur Laufzeitoptimierung, da so erreicht werden kann, daß nur für einen Bruchteil der logischen Seitenreferenzen tatsächlich physische E/A-Vorgänge erforderlich werden. Außerdem kann man bei der Abbildung von Seiten auf Blöcke (bei gleicher Granulatgröße) sehr effizient verfahren und insbesondere explizite Zwischenkopien der Daten einsparen. Bei den oberen Systemschichten lassen sich erhebliche Einsparungen erzielen, wenn die Schicht der Logischen Datenstrukturen nicht als Interpreter für SQL-Anweisungen fungieren muß, sondern zur Laufzeit durch sog. Zugriffsmodule (pro SQL-Anweisung oder Anwendungsprogramm) ersetzt wird, wobei bereits eine frühe Bindung der Zugriffsoperationen an interne Schnittstellen erfolgt (siehe Kapitel 12). Auf diese Weise läßt sich die oberste Schicht (oder gar die beiden obersten Schichten) "wegoptimieren", d. h., Anweisungen der mengenorientierten DB-Schnittstelle werden direkt auf die satzorientierte DB-Schnittstelle (oder gar die interne Satzschnittstelle) abgebildet und mit Hilfe von generierten Zugriffsmodulen als Operationsfolgen auf dieser Schnittstelle ausgeführt.
Zusätzlich ist es in einer konkreten Implementierung häufig erforderlich, die Reichweite von Optimierungsmaßnahmen auszudehnen oder globale Information zentralisiert zur Verfügung zu stellen. Als besonders wirksam hat es sich in diesem Zusammenhang erwiesen, Informationsflüsse selektiv auch über mehrere Schichten hinweg zu erlauben, in erster Linie, um eine globale Optimierung von leistungskritischen Verfahren durchführen zu können. Ein Musterbeispiel dafür ist die Kooperation von Anfrageoptimierung und DB-Pufferverwaltung. Wenn beispielsweise nach der Übersetzung und Optimierung einer SQL-Anfrage in Schicht 5 bekannt ist, welcher Operator auf welche Daten (wiederholt) zugreift, kann die DB-Pufferverwaltung in Schicht 2 mit dieser Information eine gezielte Speicherplatzallokation vornehmen und den Auswertungsaufwand ggf. durch Prefetching noch weiter reduzieren. Auch bei der zur Lastkontrolle erforderliche Abstimmung mehrerer Komponenten sowie bei bestimmten Synchronisations- und Recovery-Funktionen ist häufig eine schichtenübergreifende Kooperation angezeigt, um effiziente Protokolle anbieten zu können.
[5] Denn für DBS und ihre Anwendungen gilt folgender populärer Spruch in besonderer Weise:
"Leistung ist nicht alles, aber ohne Leistung ist alles nichts".