




16 Einführung in Parallele DBS
16.3 Arten der Parallelverarbeitung
Parallelverarbeitung für DB-Anwendungen kann auf unterschiedliche Weise klassifiziert werden. Wir betrachten hier drei Unterscheidungskriterien:
- Parallelität innerhalb von bzw. zwischen unterschiedlichen Verarbeitungsgranulaten (Transaktionen, DB-Operationen, Operatoren)
- Daten- vs. Pipeline-Parallelität
- Verarbeitungs- vs. E/A-Parallelität.
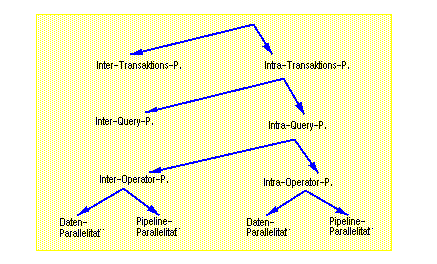
Abb. 16-3: Arten der parallelen DB-Verarbeitung
Transaktions-, Query- und Operatorparallelität
Die aus den ersten beiden Kriterien resultierenden Typen der Parallelverarbeitung sind in Abb. 16-3 dargestellt. Auf die Unterscheidung von Inter- und Intra-Transaktionsparallelität wurde bereits zu Beginn des Kapitels kurz eingegangen. Inter-Transaktionsparallelität (Mehrbenutzerbetrieb) ist als unabdingbar zu betrachten, um Durchsatzforderungen zu erfüllen. Außerdem könnte im Einbenutzerbetrieb die verfügbare CPU-Kapazität sehr vieler Prozessoren kaum ausgeschöpft werden, so daß eine inakzeptable Kosteneffektivität die Folge wäre. Intra-Transaktionsparallelität ist notwendig, um die Bearbeitungszeiten aufwendigerer Transaktionen zu verkürzen. Die weiteren Typen der Parallelisierung betreffen nur noch Intra-Transaktionsparallelität.
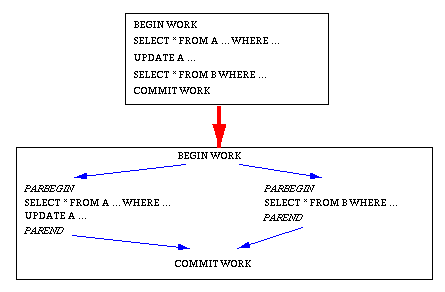
Da eine Transaktion i.a. aus mehreren DB-Operationen oder Queries besteht, kann zwischen Inter- und Intra-Query-Parallelität unterschieden werden[72]. Bei Inter-Query-Parallelität werden verschiedene DB-Operationen derselben Transaktion parallel bearbeitet. Dabei sind jedoch Präzedenzabhängigkeiten zwischen den Operationen zu beachten, um sicherzustellen, daß nur unabhängige Operationen parallel zueinander ausgeführt werden. Dies erfordert i.a. eine explizite Festlegung durch den Programmierer, welche Operationen parallel bearbeitet werden können (s. Beispiel in Abb. 16-4). Neben der Verkomplizierung der Programmierung kann mit diesem Ansatz auch meist nur eine geringe Antwortzeitverbesserung erwartet werden. Denn der maximale Parallelisierungsgrad (Speedup) ist durch die Anzahl der DB-Operationen eines Transaktionsprogramms begrenzt; bei Abhängigkeiten zwischen DB-Operationen läßt sich selbst dieser Wert nicht erreichen. Von Vorteil ist, daß für das DBS diese Form der Intra-Transaktionsparallelität einfach zu unterstützen ist, da prinzipiell keine Erweiterungen hinsichtlich der Query-Optimierung erforderlich sind. Dennoch unterstützen derzeitige DBS noch keine Inter-Query-Parallelität, wohl auch deshalb, da im SQL-Standard noch keine Anweisungen zur Parallelisierung vorgesehen sind.
Abb. 16-4: Parallelisierung von Transaktionsprogrammen (Inter-Query-Parallelität)
Relationale DBS mit ihren deskriptiven und mengenorientierten Anfragesprachen wie SQL ermöglichen die Nutzung von Parallelarbeit innerhalb einer DB-Operation (Intra-Query-Parallelität). Die Bearbeitung einer DB-Operation erfordert i.a. die Ausführung mehrerer relationaler Basisoperatoren wie Selektion, Projektion, Join etc., deren Ausführungsreihenfolge durch einen Operatorbaum beschrieben werden kann (Kap. 6.2). Damit lassen sich zwei weitere Arten der Parallelisierung unterscheiden, nämlich Inter- und Intra-Operatorparallelität. In beiden Fällen erfolgt die Parallelisierung vollkommen automatisch durch das DBS und somit transparent für den Programmierer und DB-Benutzer. Dies ist ein Hauptgrund für den Erfolg paralleler DB-Verarbeitung und stellt einen wesentlichen Unterschied zur Parallelisierung in anderen Anwendungsbereichen dar, die i.a. eine sehr schwierige Programmierung verlangen [Re92].
Beim Einsatz von Inter-Operatorparallelität werden verschiedene Operatoren einer DB-Operation parallel ausgeführt[73]. Auch hier bestehen Präzedenzabhängigkeiten zwischen den einzelnen Operatoren, die die Parallelität einschränken; jedoch sind diese im Gegensatz zur Inter-Query-Parallelität dem DBS (Query-Optimierer) bekannt. Der erreichbare Parallelitätsgrad ist in jedem Fall durch die Gesamtanzahl der Operatoren im Operatorbaum begrenzt. Bei der Intra-Operatorparallelität schließlich erfolgt die parallele Ausführung der einzelnen Basisoperatoren.
Daten- vs. Pipeline-Parallelität
Wie Abb. 16-3 zeigt, kann sowohl Inter- als auch Intra-Operatorparallelität auf Daten- oder Pipeline-Parallelität basieren[74]. Datenparallelität erfordert eine Partitionierung der Daten, so daß verschiedene Operatoren bzw. Teiloperatoren auf disjunkten Datenpartitionen arbeiten. So können z.B. Selektionsoperatoren auf verschiedenen Relationen parallel ausgeführt werden (Inter-Operatorparallelität). Eine Selektion auf einer einzelnen Relation läßt sich auch parallelisieren, wenn die Relation in mehrere Fragmente partitioniert wird (Intra-Operatorparallelität). Diese Form der Parallelisierung hat den Vorteil, daß der Parallelitätsgrad proportional zur Relationengröße erhöht werden kann.
Pipeline-Parallelität sieht eine überlappende Ausführung verschiedener Operatoren bzw. Teiloperatoren vor, um die Ausführungszeit zu verkürzen. Für benachbarte Operatoren im Operatorbaum bzw. Teiloperatoren eines Basisoperators, zwischen denen eine Erzeuger-Verbraucherbeziehung besteht, werden dabei die Ausgaben des Erzeugers im Datenflußprinzip an den Verbraucher weitergeleitet. Dabei wird die Verarbeitung im Verbraucherprozeß nicht verzögert, bis der Erzeuger die gesamte Eingabe bestimmt hat. Vielmehr werden die Sätze der Ergebnismenge fortlaufend weitergeleitet, um eine frühzeitige Weiterverarbeitung zu ermöglichen. Pipeline-Parallelität kommt primär zur Realisierung von Inter-Operatorparallelität in Betracht. Für komplexere Operatoren (z.B. Join) ist sie prinzipiell jedoch auch zur Realisierung von Intra-Operatorparallelität anwendbar.
Beispiel 16-1
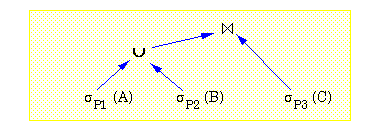
- Für den in Abb. 16-5 gezeigten Operatorbaum läßt sich Pipeline-Parallelität zwischen allen gezeigten Operatoren nutzen. So kann jedes Ergebnistupel der drei Selektionsoperatoren sofort an den nächsten Operator im Baum geleitet werden, um dort eine Weiterverarbeitung zu ermöglichen. Ergebnistupel des Vereinigungsoperators können ferner sofort an den Join-Operator geschickt werden. Daneben lassen sich natürlich die drei Selektionsoperatoren parallel zueinander ausführen, da sie unterschiedliche Relationen betreffen (Datenparallelität). Zudem kann ggf. Datenparallelität für jede Selektion genutzt werden (Intra-Operatorparallelität).
Abb. 16-5: Beispiel eines parallelisierbaren Operatorbaumes
Pipeline-Parallelität verursacht jedoch einen hohen Kommunikations-Overhead, wenn jedes Ergebnistupel einzeln weitergegeben wird, vor allem wenn die Operatoren in Prozessen verschiedener Rechner ausgeführt werden (Shared-Nothing bzw. Shared-Disk). Ohne Pipeline-Parallelität verzögert sich jedoch der Start eines Operators bis die Ergebnismengen der Vorgängeroperatoren vollständig vorliegen. Zudem kann es dabei zu erheblichem Mehraufwand an E/A im Falle großer Ergebnismengen kommen, wenn diese auf Platte zwischengespeichert werden müssen. Ein Kompromiß besteht darin, den Kommunikationsaufwand der Pipeline-Parallelität dadurch zu beschränken, indem jeweils mehrere Ergebnistupel gebündelt übertragen werden.
Dennoch sind die mit Pipeline-Parallelität erreichbaren Speedup-Werte meist gering, da in relationalen DB-Operationen selten mehr als 10 Operatoren auf diese Weise überlappt ausgeführt werden können [DG92]. Dies ist auch dadurch bedingt, daß einige Operatoren zur Unterbrechung einer Pipeline führen, da sie die vollständigen Ergebnismengen von Vorgängeroperatoren benötigen, bevor sie ein Ergebnis weitergeben können. Dies sind insbesondere Sortieroperatoren sowie Operatoren zur Duplikateliminierung oder Berechnung von Aggregatfunktionen. Schließlich bestehen oft erhebliche Unterschiede in den Ausführungszeiten verschiedener Operatoren, so daß der erreichbare Speedup stark beeinträchtigt wird (Skew-Effekt).
Verarbeitungs- vs. E/A-Parallelität
Die bisher diskutierten Parallelisierungsformen entsprechen unterschiedlichen Arten von Verarbeitungsparallelität, die sich vor allem auf die Nutzung mehrerer Prozessoren bezieht. Diese Ansätze können jedoch nur dann ihre Wirksamkeit entfalten, wenn sie durch eine entsprechende E/A-Parallelität beim Externspeicherzugriff unterstützt werden. Denn ansonsten würde die Sequentialisierung der Plattenzugriffe sämtliche Parallelitätsgewinne bei den CPU-bezogenenen Verarbeitungsanteilen wieder zunichte machen. So führt z.B. die parallele Abwicklung von Teiloperationen, welche den Zugriff auf dieselbe Platte erfordern, primär zu erhöhten Wartezeiten beim Plattenzugriff, statt zu einer Verkürzung der Antwortzeit.
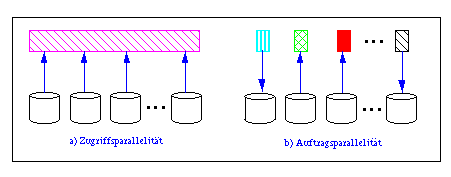
Man kann grob zwei Arten von E/A-Parallelität unterscheiden, welche durch eine geeignete Datenverteilung über mehrere Platten zu unterstützen sind. Zum einen ist es notwendig, E/A-Vorgänge auf große Datenmengen parallel von mehreren Platten zu bedienen, um kurze Zugriffszeiten zu erhalten (Abb. 16-6a). Diese Art der E/A-Parallelität wurde in [WZ93] als Zugriffsparallelität bezeichnet und kommt vor allem bei der Intra-Operatorparallelität zum Tragen. Daneben sollte ein möglichst hoher Durchsatz bzw. hohe E/A-Raten für unabhängige E/A-Aufträge erzielt werden, indem diese möglichst von verschiedenen Platten bedient werden (Abb. 16-6b). Diese sogenannte Auftragsparallelität ist für Inter-Transaktionsparallelität erforderlich, jedoch auch für Inter-Query- sowie Inter-Operatorparallelität. Beide Formen der E/A-Parallelität dienen primär der Datenparallelität, also dem parallelen Zugriff auf disjunkte Datenmengen. Pipeline-Parallelität arbeitet dagegen auf Zwischenergebnissen während der Anfrageverarbeitung und kommt idealerweise ohne Externspeicherzugriffe aus.
Abb. 16-6: Zugriffs- vs. Auftragsparallelität
[72] Für Ad-Hoc-Anfragen ist Inter-Query-Parallelität offenbar nicht anwendbar. Für solche Anfragen sind Intra-Transaktions- und Intra-Query-Parallelität gleichbedeutend.
[73] Gelegentlich wird Inter-Operatorparallelität als Funktionsparallelität bezeichnet.
[74] Datenparallelität wird auch als horizontale, Pipeline-Parallelität als vertikale Parallelität bzw. Datenfluß-Parallelität bezeichnet.