




17 Datenverteilung in Parallelen DBS
17.1 Bestimmung des Verteilgrades
Der Verteilgrad (degree of declustering) D einer Relation legt fest, über wieviele Partitionen (Rechner, Platten) diese verteilt wird. Er ist von entscheidender Bedeutung für die Leistungsfähigkeit, da vor allem Selektionsoperationen häufig auf allen D Partitionen auszuführen sind. Bei der Bestimmung von D sind teilweise widersprüchliche Forderungen wie Unterstützung von Intra-Transaktionsparallelität, geringer Kommunikationsaufwand sowie Lastbalancierung zu berücksichtigen (Kap. 5.7). So ist zur Unterstützung von Intra-Transaktionsparallelität prinzipiell eine "breite" Verteilung einer Relation über viele Knoten wünschenswert. Dies wird etwa mit dem einfachen Ansatz des "full declustering" erreicht, bei dem eine Relation über alle N Knoten bzw. Platten verteilt wird (D=N). Für sehr große Relationen könnte ein kleinerer Verteilgrad auch eine ungünstige Lastbalancierung verursachen, da nicht die Kapazität des gesamten Systems genutzt würde und in den Rechnern, auf die die Bearbeitung beschränkt wird, verstärkte Behinderungen für andere Transaktionen hervorgerufen würden. Auf der anderen Seite führt jedoch ein hoher Verteilgrad zwangsweise zu einem hohen Kommunikationsaufwand zum Starten von Teiloperationen sowie zum Zurückliefern von Ergebnissen. Dieser Aufwand kann für kleinere Relationen sowie für selektive Anfragen, die z.B. lediglich einen Satz als Ergebnis liefern, prohibitiv teuer sein. Für solche Relationen sollte daher eine Allokation zu einer Teilmenge der Rechner erfolgen. Selektive Anfragen (auch auf großen Relationen) sollten auf möglichst wenige Knoten beschränkt werden können (Unterstützung von Lokalität).
Die Diskussion zeigt, daß unterschiedliche Anfragetypen i.a. unterschiedliche Verteilgrade erfordern. Bei der Datenverteilung muß daher für Shared-Nothing-Systeme ein Kompromißwert festgelegt werden, der eine "durchschnittliche" Anfrage gut bedient. Um den optimalen Verteilgrad für eine bestimmte Anfrage bestimmen zu können, ist eine Abschätzung ihrer Antwortzeit in Abhängigkeit des Verteilgrades, der bei Shared-Nothing meist auch dem Parallelitätsgrad p entspricht, vorzunehmen. Nach [WFA93] läßt sich für den Einbenutzerbetrieb die Antwortzeit R einer über p Rechner parallelisierten Anfrage unter bestimmten Annahmen mit folgender Formel charakterisieren[75]:
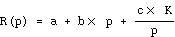
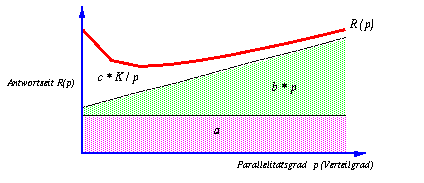
Demnach setzt sich die Antwortzeit aus drei Komponenten zusammen, die in Abb. 17-1 separiert dargestellt sind. Der konstante Anteil a umfaßt die nicht parallelisierbaren Anteile der Anfrage (Initialisierungskosten u.ä.). Die zweite Antwortzeitkomponente entspricht der Zeit zum Starten und Beenden der p Teiloperationen; dieser Aufwand steigt i.a. linear mit dem Parallelisierungs- und Verteilgrad. Die eigentlichen Nutzarbeit wird durch c *K abgeschätzt und soll proportional zu der Anzahl zu verarbeitender Tupel K sein. Die Bearbeitungsdauer dieses Anteil wird durch die Parallelisierung idealerweise linear verkürzt. Die Koeffizienten a, b, c und K sind u.a. abhängig von DB- und Anfragemerkmalen, wie Relationengröße, Nutzbarkeit eines Indextyps, Selektivität der Anfrage etc. Weiterhin gehen die benötigten Instruktionen für gewisse Operationen (Kommunikation, etc.), sowie Hardware-Merkmale (CPU-, Platten-, Netzwerkgeschwindigkeit) ein. Auf die Einzelheiten der Festlegung soll hier verzichtet werden; eine genaue Beschreibung für Selektionsoperationen (mit und ohne Indexnutzung) sowie für Join-Anfragen findet sich in [Ma93].
Abb. 17-1: Antwortzeitzusammensetzung in Abhängigkeit vom Verteilgrad
Wurde für eine Anfrage in dieser Weise eine Antwortzeitabschätzung vorgenommen, läßt sich der optimale Verteilgrad dadurch bestimmen, indem man berechnet, welcher p-Wert die Antwortzeitfunktion R (p) minimiert. Durch Bilden der ersten Ableitung von R (p) und Gleichsetzen mit Null ergibt sich:
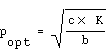
Die Formel zeigt, daß das Optimum unabhängig vom konstanten Anteil a ist, sondern im wesentlichen vom Verhältnis zwischen der Nutzarbeit c * K und dem Parallelisierungs-Overhead b bestimmt wird. Um den Verteilgrad D der Relation festzulegen, bestimmt man in der skizzierten Weise den optimalen Wert popt für die wichtigsten Anfragetypen. Daraus wird dann ein gewichteter Mittelwert gebilden, bei dem sich das Gewicht eines Anfragetyps aus seinem geschätzten Anteil an der Gesamtlast ergibt.
Beispiel 17-1
- Abb. 17-2 zeigt die mit den Formeln aus [Ma93] bestimmte Antwortzeitentwicklung sowie die zugehörigen Speedup-Werte für drei unterschiedliche Selektionsoperationen auf einer Relation von 1 Million Tupel. Man erkennt, daß die Parallelisierung für die verschiedenen Anfragetypen unterschiedlich effektiv ist und unterschiedliche Optima bezüglich des Verteilgrades bestehen. Besonders effektiv ist die Parallelisierung, wenn kein Index genutzt werden kann (Relationen-Scan); hier wird ein nahezu linearer Speedup erzielt. Für eine unterstellte Prozessoranzahl von 64 gilt für diesen Anfragetyp popt = 64. Im Falle der Index-Scans kann die Verarbeitung auf die sich qualifizierenden Tupel beschränkt werden, so daß bessere Antwortzeiten als beim Relationen-Scan erreicht werden. Hier sinkt der Nutzen der Parallelisierung mit zunehmender Selektivität der Anfrage; im Beispiel gilt popt=52 (1% Selektivität) bzw. popt = 16 (0,1%). Wenn die beiden Index-Scans jeweils 40% der Zugriffe auf die Relation ausmachen und für 20% der Zugriffe ein vollständiger Relationen-Scan erforderlich ist, ergibt sich als gewichteter Mittelwert
- D = 0,4*16 + 0,4*52 + 0,2*64 = 40.
Abb. 17-2: Bestimmung des optimalen Verteilgrades für drei Anfragetypen

[75] Dabei wird insbesondere eine gleichmäßige Verteilung der Daten unter den Partitionen sowie eine gleichmäßige Referenzverteilung unterstellt.