




3.1 Shared-Everything, Shared-Disk, Shared-Nothing
3.1.2 Technische Probleme
Die vorgestellten Klassifikationsmerkmale ergeben die Unterscheidung zwischen drei verbreiteten Typen von Mehrrechner-DBS (Abb. 3-1), die zusammenfassend wie folgt charakterisiert werden können:
- Shared-Everything (Multiprozessor-DBS):
Die DB-Verarbeitung erfolgt durch ein DBVS auf einem Multiprozessor.
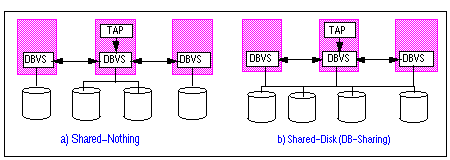
- Shared-Nothing (Database Distribution, DB-Distribution, Abb. 3-3a):
Die DB-Verarbeitung erfolgt durch mehrere, i.a. lose gekoppelte Rechner, auf denen jeweils ein DBVS abläuft. Die Externspeicher sind unter den Rechnern partitioniert, so daß jedes DBVS nur auf Daten der lokalen Partition direkt zugreifen kann. Die Rechner können lokal oder geographisch verteilt angeordnet sein. Multiprozessoren sind als Rechnerknoten möglich, das heißt, die lokalen DBVS können vom Typ "Shared-Everything" sein.
- Shared-Disk (Database Sharing, DB-Sharing, Abb. 3-3b):
Wie bei Shared-Nothing liegt eine Menge von Verarbeitungsrechnern mit je einem DBVS vor, wobei jeder Rechner ein Multiprozessor sein kann. Es liegt eine gemeinsame Externspeicherzuordnung vor, so daß jedes DBVS direkten Zugriff auf die gesamte Datenbank hat. Die Rechner sind i.a. lokal innerhalb eines Clusters verteilt, wobei entweder eine lose oder nahe Rechnerkopplung möglich ist.
Von diesen Ansätzen ist die Realisierung von Mehr- oder Multiprozessor-DBS (Shared-Everything) mit Abstand am einfachsten, da das Betriebssystem die Verteilung bereits weitgehend verbirgt ("single system image"). Folglich ergeben sich kaum Änderungen bezüglich den in Kap. 2.1.2 und Kap. 2.1.3 vorgestellten Funktionen zentralisierter DBVS. Allerdings verlangt die volle Nutzung eines Multiprozessors eine DB-Verarbeitung in mehreren Prozessen. Der DBVS-Code sowie die Datenstrukturen des DBVS (insbesondere DB-Puffer und Sperrtabelle) werden im gemeinsamen Hauptspeicher für alle DBVS-Prozesse zugänglich gehalten. Insbesondere für den Zugriff auf die DBVS-Datenstrukturen ist eine Synchronisation zwischen den Prozessen durchzuführen, z.B. über Semaphore [Hä79]. Weiterhin ist eine Zuordnung abzuarbeitender DB-Operationen zu den DBVS-Prozessen vorzunehmen (Lastbalancierung). Dies läßt sich z.B. durch Verwendung einer gemeinsamen Auftragswarteschlange für DB-Operationen im Hauptspeicher geeignet realisieren, auf die alle DBVS-Prozesse Zugriff haben. Daneben sind Erweiterungen bei der Query-Optimierung erforderlich, wenn eine Parallelarbeit innerhalb von Transaktionen auf mehreren Prozessoren unterstützt werden soll.
Die meisten kommerziellen DBS unterstützen den Shared-Everything-Ansatz, das heißt, sie können Multiprozessoren zur DB-Verarbeitung nutzen.
Abb. 3-3: Shared-Nothing vs. Shared-Disk
Der Shared-Nothing-Ansatz erfordert, die Daten (Datenbank) unter mehrere Rechner bzw. DBVS aufzuteilen. Hierzu sind zunächst die Einheiten der Datenverteilung oder Fragmente festzulegen. Danach wird im Rahmen der Allokation bestimmt, welchen Rechnern die Fragmente zugeordnet werden, wobei im Falle replizierter Datenbanken einzelne Fragmente mehreren Rechnern zugeteilt werden können. Die Bearbeitung von DB-Operationen muß auf die vorgenommene Datenverteilung abgestimmt werden, da jedes DBVS nur auf Daten der lokalen Partition zugreifen kann. Dies erfordert die Erstellung verteilter bzw. paralleler Ausführungspläne durch das DBVS (Query-Übersetzung und -Optimierung). Darüber hinaus ist durch die DBVS ein rechnerübergreifendes Commit-Protokoll zu unterstützen, um die Atomarität verteilter Transaktionen zu gewährleisten. Weitere technische Probleme betreffen die Verwaltung von Katalogdaten, die Behandlung globaler Deadlocks sowie die Wartung replizierter Datenbanken. Die Lösung dieser Probleme wurde vor allem für Verteilte Datenbanksysteme intensiv untersucht, die im Teil II dieses Buchs ausführlich behandelt werden.
Die großen Forschungsanstrengungen bezüglich Verteilter Datenbanksysteme führten zur Entwicklung zahlreicher Prototypen sowie einiger kommerzieller Produkte (Kap. 19). Implementierungen lokal verteilter Shared-Nothing-Systeme (Bsp.: Teradata) wurden vor allem im Hinblick auf die Realisierung von Hochleistungssystemen entwickelt, insbesondere zur parallelen Bearbeitung komplexer DB-Anfragen.
In Shared-Disk-DBS ist aufgrund der gemeinsamen Externspeicherzuordnung keine physische Datenaufteilung unter den Rechnern vorzunehmen. Insbesondere können sämtliche DB-Operationen einer Transaktion innerhalb eines Rechners abgearbeitet werden, so daß keine verteilten Ausführungspläne und kein verteiltes Commit-Protokoll zu unterstützen sind. Kommunikation zwischen den DBVS wird v.a. zur globalen Synchronisation der DB-Zugriffe notwendig. Ein weiteres Problem stellt die Behandlung sogenannter Pufferinvalidierungen dar, die sich dadurch ergeben, daß jedes DBVS Seiten der gemeinsamen Datenbank in seinem lokalen Hauptspeicherpuffer hält. Weitere technische Probleme betreffen Logging und Recovery sowie Lastverteilung und -balancierung. Die Realisierung dieser Funktionen wird im Teil IV dieses Buches ausführlich behandelt.
Der Shared-Disk-Ansatz hat in der Forschung im Vergleich mit Shared-Nothing (und Verteilten DBS) ein eher geringes Interesse gefunden. Dies steht jedoch im Gegensatz zur Bedeutung dieses Ansatz in der Praxis, wo er von einer zunehmenden Anzahl von DBS unterstützt wird (s. Kap. 19).