




Mehrrechner-Datenbanksysteme
20 Lösungen zu den Übungsaufgaben
Aufgabe 3-1 : Shared-Everything
- Datenbank- und Log-E/A während eines kritischen Abschnittes muß vermieden werden; Vermeidung von Paging-E/A sowie Zeitscheibenentzug im kritischen Abschnitt würde jedoch Kooperation mit dem Betriebssystem erfordern. Generell kann Konfliktgefahr durch Verwendung kleiner Sperrgranulate (vieler Semaphore) reduziert werden; z.B. nicht nur 1 Semaphor für die gesamte Sperrtabelle, sondern ein Semaphor pro Hash-Klasse.
Aufgabe 3-2 : Shared-Nothing vs. Shared-Disk
- Leistungsfähigkeit: größere Möglichkeiten zur Lastbalancierung für Shared-Disk, da jede DB-Operation von jedem DBVS abarbeitbar ist; mehr Einsatzmöglichkeiten einer nahen Rechnerkopplung
- Erweiterbarkeit: Verknüpfung sehr vieler Rechner mit allen Platten aufwendig für Shared-Disk; erfordert nachrichten-basierte E/A mit sehr leistungsfähigem, skalierbarem Kommunikationsnetzwerk. Bei Shared-Nothing erfordert Hinzunahme von Rechnern aufwendige physische Neuverteilung der Datenbank
- Verfügbarkeit: Datenbank nach Rechnerausfall bei Shared-Disk weiterhin erreichbar, bei Shared-Nothing nur, falls Replikation vorliegt bzw. Daten noch umverteilt werden können. Komplexe Recovery-Protokolle für Shared-Disk (globaler Log); aufwendiges Commit-Protokoll für Shared-Nothing
- Administration: Festlegung und Anpassung der physischen Datenbankverteilung bei Shared-Nothing i.a. vom Systemverwalter zu veranlassen
Aufgabe 4-1: Katalogverwaltung
- Neben partitionierten Katalogen eignet sich vor allem eine vollständige Replikation, da hiermit lesende Katalogzugriffe stets lokal abgewickelt werden können. Selbst die Replizierung von Angaben des internen Schemas ist zu empfehlen, um an jedem Knoten eine schnelle Übersetzung und Optimierung von Anfragen zu erreichen. Da Änderungen von Katalogdaten eher selten sind, ist der Aufwand zur Wartung der Replikation vertretbar.
Aufgabe 4-2 Namensauflösung in R*
- a) Erst die Kombination von <Benutzername> und <Benutzerknoten> ergibt globale Eindeutigkeit. Somit können auch Benutzernamen lokal vergeben werden. Ohne <Benutzerknoten> wäre es weiterhin nicht möglich, daß zwei Benutzer mit demselben lokalen Namen (<Benutzername>) an einem bestimmten Knoten verschiedene Objekte mit gleichem <Objektname> erzeugen.
- b)
-

Aufgabe 4-3 Namensverwaltung (SQL92)
- Globale Eindeutigkeit ließe sich erreichen, wenn Katalognamen global eindeutig sind. Allerdings ist auch dann eine lokale Überprüfung von Objektnamen nur möglich, wenn alle Datenbanken eines (SQL92-)Katalogs auf einen Rechner begrenzt werden (d.h., Kataloge als Verteilungsgranulate dienen). Dies ist jedoch viel zu restriktiv, da selbst einzelne Datenbanken und Relationen über mehrere Knoten zu verteilen sind.
Durch Erweiterung von Objektnamen um den Knotennamen kann in ähnlicher Weise wie in Kap. 4.4 diskutiert globale Eindeutigkeit erreicht werden.
Aufgabe 4-4 Herausnahme von Knoten aus dem System
- Sämtliche Daten, die an dem betroffenen Knoten erzeugt wurden, sind davon betroffen. Es genügt prinzipiell, die Katalogdaten an einen anderen (oder mehrere) Knoten zu übertragen und in den Synonymtabellen die Knotennamen anzupassen. Sämtliche Daten und Anwendungen des abzuschaltenden Knotens sind natürlich auch auf andere Rechner zu migrieren.
Aufgabe 4-5 Synonyme
- Im Extremfall sind für alle (an mehreren Knoten benötigten) DB-Objekte Synonyme zu definieren. Weiterhin muß die Replikation von Synonymangaben gewartet werden. Generell ergibt sich eine Verkomplizierung der Systemadministration.
Aufgabe 4-6 Nutzung standardisierter Directory-Dienste
- Zur Nutzung von Directory-Diensten wie X.500 wären globale Namen auf die X.500-Konventionen abzubilden. Allerdings würde damit nur ein Bruchteil der zur Katalogverwaltung notwendigen Funktionalität abgedeckt. Insbesondere ist es notwendig, die Katalogdaten transaktionsbasiert zu verarbeiten und auf ihnen selbst DB-Anfragen zu verarbeiten. Weiterhin ist keine ausreichende Flexibilität gegeben zur Spezifizierung komplexer Verteilungskriterien, wie im Falle fragmentierter Relationen benötigt.
Aufgabe 5-1: Korrektheit der abgeleiteten horizontalen Fragmentierung
- S-Tupel mit Nullwerten als Fremdschlüssel finden keinen Verbundpartner in R. Um die Vollständigkeit der Fragmentierung zu gewährleisten, sind diese S-Tupel einem (oder mehreren) eigenen Fragment(en) zuzuordnen. Für die Join-Berechnung spielen diese S-Tupel keine Rolle, außer wenn ein äußerer Verbund (outer join) zu berechnen ist, bei dem sämtliche Tupel der beteiligten Relationen im Ergebnis zu berücksichtigen sind.
Aufgabe 5-2 Abgeleitete horizontale Fragmentierung
- Horizontale Fragmentierung von ABT:
- ABT1 =
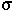 AORT = "KL" (ABT)
AORT = "KL" (ABT)
ABT2 =  AORT = "F" (ABT)
AORT = "F" (ABT)
ABT3 =  AORT = "L" (ABT).
AORT = "L" (ABT).
- Abgeleitete horizontale Fragmentierung von PERSONAL (für den Fremdschlüssel ANR seien keine Nullwerte zulässig):
- PERSONAL1 = PERSONAL
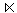 ABT1
ABT1
PERSONAL2 = PERSONAL 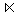 ABT2
ABT2
PERSONAL3 = PERSONAL 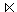 ABT3.
ABT3.
- Abgeleitete horizontale Fragmentierung von PMITARBEIT:
- PMITARBEIT1 = PMITARBEIT
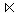 PERSONAL1
PERSONAL1
PMITARBEIT2 = PMITARBEIT 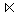 PERSONAL2
PERSONAL2
PMITARBEIT3 = PMITARBEIT 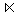 PERSONAL3.
PERSONAL3.
- Im Falle einer horizontalen Fragmentierung von PROJEKT könnte für PMITARBEIT eine abgeleitete horizontale Fragmentierung auch bezüglich PROJEKT erfolgen. Dies wäre vorteilhafter als die auf PERSONAL ausgerichtete Fragmentierung, wenn häufiger eine Join-Berechnung mit PROJEKT als mit PERSONAL vorzunehmen ist.
Aufgabe 5-3 Hybride Fragmentierung
- Vertikale Fragmentierung von PERSONAL1 (PERSONAL2 und PERSONAL3 analog):
- PERSONAL11 =
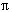 PNR, PNAME, ANR, BERUF (PERSONAL1)
PNR, PNAME, ANR, BERUF (PERSONAL1)
- PERSONAL12 =
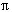 PNR, GEHALT (PERSONAL1)
PNR, GEHALT (PERSONAL1)
Aufgabe 5-4 Bestimmung der Datenallokation
- Allokation: F1 -> R2, F4 -> R3, F3 -> R1, F2 -> R1 (da R2 und R3 ansonsten überlastet)
- CU1=21,925 MIPS (73 %); CU2=22,85 MIPS (76 %); CU3=19,925 MIPS (66 %)
- Anteil lokaler Zugriffe: 53 %; Kommunikations-Overhead: 12,3 MIPS
Aufgabe 6-1: Normalisierung
- Konjunktive Normalform:
- (PNAME LIKE "M%"
 PNR > 550
PNR > 550  BERUF="Programmierer")
BERUF="Programmierer") 
(PNAME LIKE "M%"  PNR > 550
PNR > 550  GEHALT < 80000)
GEHALT < 80000) 
(PNAME LIKE "M%"  BERUF="Programmierer"
BERUF="Programmierer"  GEHALT < 80000)
GEHALT < 80000) 
(PNAME LIKE "M%"  GEHALT < 80000)
GEHALT < 80000) 
(BERUF = "Techniker"  PNR > 550
PNR > 550  BERUF="Programmierer")
BERUF="Programmierer") 
(BERUF = "Techniker"  PNR > 550
PNR > 550  GEHALT < 80000)
GEHALT < 80000) 
(BERUF = "Techniker"  BERUF="Programmierer"
BERUF="Programmierer"  GEHALT < 80000)
GEHALT < 80000) 
(BERUF = "Techniker"  GEHALT < 80000).
GEHALT < 80000).
- Disjunktive Normalform:
- (PNAME LIKE "M%"
 BERUF = "Techniker")
BERUF = "Techniker") 
(PNR > 550  GEHALT < 80000)
GEHALT < 80000) 
(BERUF="Programmierer"  GEHALT < 80000).
GEHALT < 80000).
Aufgabe 6-2 Vereinfachung
- Es ergibt sich die leere Ergebnismenge wegen den gegensätzlichen Prädikaten bzgl. GEHALT
Aufgabe 6-3 Operatorbaum und Rekonstruktion
- Neben Selektionen wurden auch Projektionen vorgezogen. Es ist dabei darauf zu achten, daß die für die Join-Bearbeitung sowie für die Ausgabe benötigten Attribute erhalten bleiben. Die Reihenfolge der Join-Operationen wurde nicht optimiert, da über die Kardinalitäten keine Aussagen gemacht wurden.
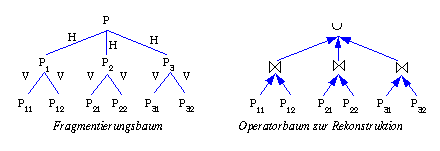
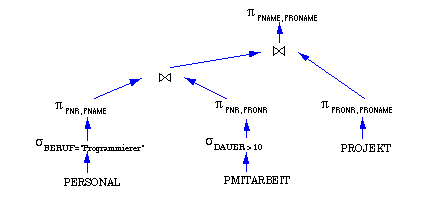
Aufgabe 6-4 Daten-Lokalisierung (abgeleitete Fragmentierung)
Aufgabe 6-5 Daten-Lokalisierung (hybride Fragmentierung)
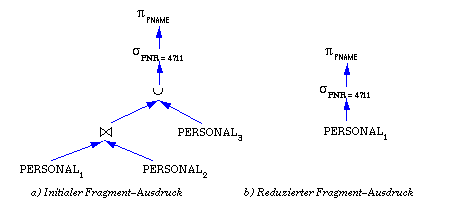
Aufgabe 6-6 Einfache Join-Strategien
- S1 (Ship Whole, Join-Berechnung am R-Knoten):
- #Nachrichten = 2; #AW = 1000*5 = 5 000.
- S2 (Ship Whole, Join-Berechnung am S-Knoten):
- #Nachrichten = 2; #AW = 10 000 * 5 =50 000.
- F1 (Fetch As Needed; Join-Berechnung am R-Knoten):
- #Nachrichten = 10 000*2=20 000; #AW = 10 000 * 0.001 * 1000 * 5 = 50 000.
- F2 (Fetch As Needed; Join-Berechnung am S-Knoten):
- #Nachrichten = 1000*2= 2 000; #AW = 1000 * 0.001 * 10000 * 5=50 000.
- => S1 ist optimal.
Aufgabe 6-7 Ship-Whole vs. Semi-Join vs. Bitvektor-Join
- Ship-Whole; Join-Berechnung an Knoten KPMITARBEIT
- - K -> KPMITARBEIT : Nachricht zum Query-Start
- KPMITARBEIT -> KPERSONAL: Anfordern der PERSONAL-Daten
- KPERSONAL -> KPMITARBEIT : 1000*0.2*3 = 600 AW
- Join-Berechnung an KPMITARBEIT .
- KPMITARBEIT -> K: Join-Ergebnis (200*0.75*2*5=1500 AW)
=> #Nachrichten=4; #AW=2100.
- Ship-Whole; Join-Berechnung an Knoten K
- - K -> KPMITARBEIT : Anfordern der PMITARBEIT-Daten
- K -> KPERSONAL: Anfordern der PERSONAL-Daten
- KPMITARBEIT -> K: 1500*3=4500 AW
- KPERSONAL -> K : 1000*0.2*3 = 600 AW
- Join-Berechnung an K
=> #Nachrichten=4; #AW=5100.
- Semi-Join; Join-Berechnung an Knoten KPERSONAL
- - K -> KPERSONAL : Nachricht zum Query-Start
- KPERSONAL -> KPMITARBEIT : 1000*0.2 = 200 AW Verbundattributwerte
- KPMITARBEIT -> KPERSONAL: 200*0.75*2*3=900 AW (Verbundpartner)
- Join-Berechnung an KPERSONAL .
- KPERSONAL -> K: Join-Ergebnis (200*0.75*2*5=1500 AW)
=> #Nachrichten=4; #AW=2600.
- Semi-Join; Join-Berechnung an Knoten K
- - K -> KPMITARBEIT : Anfordern der reduzierten Daten
- K -> KPERSONAL: Anfordern der reduzierten Daten
- KPMITARBEIT -> KPERSONAL: 750 AW Verbundattributwerte
- KPERSONAL -> K : 750*0.2*3=450 AW (Verbundpartner)
- KPERSONAL -> KPMITARBEIT : 1000*0.2 = 200 AW Verbundattributwerte
- KPMITARBEIT -> K: 200*0.75*2*3=900 AW (Verbundpartner)
- Join-Berechnung an K
=> #Nachrichten=6; #AW=2300.
- Bitvektor-Join; Join-Berechnung an Knoten K
- wie vor, jedoch wird in Schritten 3 und 5 jeweils der Bitvektor übertragen (-> 10 AW);
in Schritt 4 (6) erhöht sich der Übetragungsumfang auf ca. 475 (945) AW.
=> #Nachrichten=6; #AW=1430.
Aufgabe 6-8 Semi-Join-Berechnung an drittem Knoten K
- a)
- 1. In KR: Bestimmung der Verbundattributwerte
 V (R) und Übertragung an KS
V (R) und Übertragung an KS
2. In KS: Bestimmung von Z1 = (S 
 V (R)) = (S
V (R)) = (S 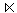 R) und Übertragung an K
R) und Übertragung an K
3. In KS: Bestimmung der Verbundattributwerte 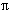 V (Z1) und Übertragung an KR
V (Z1) und Übertragung an KR
4. In KR: Bestimmung von Z2 = (R 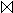
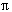 V (Z1)) = (R
V (Z1)) = (R 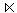 S) und Übertragung an K
S) und Übertragung an K
5. In K: Bestimmung von Z1 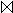 Z2 = R
Z2 = R 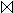 S.
S.b)
- #AW=17 (statt 19), da zwischen KS und KR in Schritt 3 nur noch zwei
Attributwerte (1, 5) statt vier übertragen werden.
Aufgabe 6-9 Mehr-Wege-Join
- Zu berechnen ist folgende gekettete Join-Anfrage
-
 BERUF = "Programmierer" (PERSONAL)
BERUF = "Programmierer" (PERSONAL) 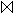 PMITARBEIT
PMITARBEIT 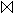 PROJEKT.
PROJEKT.
Wir bertrachten zwei Ship-Whole-Strategien sowie die Semi-Join-Strategie mit vollständiger Reduzierung:
- S1:
- Join-Berechnung an KPERSONAL; Anfordern und Transfer von
PMITARBEIT (1500*3=4500AW) und PROJEKT (200*3=600 AW).
=> #Nachrichten=4; #AW=5100.
- S2:
- Start der Join-Berechnung an KPMITARBEIT; Anfordern und Transfer von PROJEKT
(200*3=600 AW) und 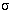 BERUF = "Programmierer" (PERSONAL) (100*4=400 AW);
BERUF = "Programmierer" (PERSONAL) (100*4=400 AW);
Join-Ergebnis (100*0.75*2*10=1500 AW) an KPERSONAL
=> #Nachrichten=6; #AW=2500.
- SJ:
- KPERSONAL -> KPMITARBEIT : 1000*0.1 = 100 AW Verbundattributwerte.
KPMITARBEIT -> KPROJEKT: 100*0.75*2=150 AW Verbundattributwerte
KPROJEKT -> KPMITARBEIT : 150 AW Verbundattributwerte
KPMITARBEIT -> KPERSONAL: 75 AW Verbundattributwerte
KPROJEKT -> KPERSONAL : Transfer der reduzierten Relation (150*3=450 AW)
KPMITARBEIT -> KPERSONAL: Transfer der reduzierten Relation (150*3=450 AW)
Join-Berechnung an KPERSONAL
=> #Nachrichten=6; #AW=1375.
Aufgabe 7-1: Presumed-Abort- vs. Standard-2PC

- Presumed-Abort schneidet im Aufwand für gescheiterte Transaktionen (Fall c) besser ab, da die ACK-Nachrichten und Ende-Sätze eingespart werden. Im Erfolgsfall verursacht der Zwischenknoten in der Hierarchie für Presumed-Abort einen zusätzlichen Log-Vorgang für den Ende-Satz.
Aufgabe 7-2 Nicht-blockierendes 2PC durch Prozeß-Paare
- Für ein zentralisiertes 2PC sind drei Nachrichten vom Koordinator zum Backup-TM zu schicken: vor Absenden der PREPARE-Nachrichten, vor Schreiben des Commit-Ergebnisses und vor Schreiben des Ende-Satzes. Der Erhalt dieser Nachrichten ist vom Backup-TM jeweils zu quittieren, so daß insgesamt 6 zusätzliche Nachrichten anfallen. Dies verursacht für N<3 einen höheren Aufwand als 3PC, für N>3 ist der Aufwand geringer. Da der Koordinator jeweils synchron auf die Quittung warten muß, ergibt sich jedoch eine signifikante Antwortzeiterhöhung, vor allem wenn die Kommunikation mit dem Backup über ein Weitverkehrsnetz erfolgen muß.
Aufgabe 8-1: Verbesserung von BOCC
- Es wird ein Transaktionszähler TNC geführt, dessen Wert Änderungstransaktionen als Commit-Zeitstempel zugewiesen und anschließend inkrementiert wird. Objekte besitzen einen Schreibzeitstempel WTS, der dem Commit-Zeitstempel der ändernden Transaktion entspricht. Für jedes gelesene Objekt x von Transaktion Tj wird der Schreibzeitstempel der gelesenen Version tsj(x) im Read-Set vermerkt. Bei der Validierung ist lediglich zu prüfen, ob die gesehenen Objektversionen noch aktuell sind.
Insgesamt ergibt sich folgende Commit-Behandlung für Transaktion Tj :
VALID := true;
for (alle x in RS (Tj)) do
if tsj (x) < WTS (x) then VALID := false;
end;
if not VALID then Rollback (Tj);
else if WS (Tj) 
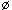 then do { Änderungstransaktion }
cts (Tj) := TNC; { Commit-Zeitstempel }
TNC := TNC + 1;
for (alle x in WS (Tj)) do
WTS (x) := cts (Tj);
end;
Schreibphase für Tj ;
end;
then do { Änderungstransaktion }
cts (Tj) := TNC; { Commit-Zeitstempel }
TNC := TNC + 1;
for (alle x in WS (Tj)) do
WTS (x) := cts (Tj);
end;
Schreibphase für Tj ;
end;
- Für den Zugriff auf die aktuellen WTS-Werte sind nicht die Objekte selbst zu referenzieren, vielmehr können diese Werte in einer Tabelle vermerkt werden. Darin sind die WTS-Werte nur für diejenigen Änderungstransaktionen zu führen, die seit dem Start der ältesten (laufenden) Transaktion validiert haben.
Aufgabe 8-2 FOCC
- Für jede Transaktion wird die Anzahl bereits erfolgter Rücksetzungen mitgeführt. Im Konfliktfall wird stets die Transaktion mit der geringeren Anzahl von Rücksetzungen abgebrochen. Damit ist der Transaktion mit der höchsten Anzahl von Rücksetzungen das Durchkommen sicher. Das Verhungern einer bereits (mehrfach) zurückgesetzten Transaktion wird verhindert, da sie irgendwann die meisten Rücksetzungen von allen unbeendeten Transaktionen aufweist.
Aufgabe 8-3 Schmutzige vs. unsichere Änderungen
- Schmutzige Änderungen stammen von laufenden Transaktionen, deren Commit daher noch ungewiß ist. Unsichere Änderungen sind eine Variante schmutziger Änderungen, die im verteilten Fall relevant wird. Sie bezeichnen Änderungen von Transaktionen, die lokal bereits erfolgreich zu Ende gekommen sind, deren globales Commi jedoch noch ungewiß ist.
- Bei OCC werden Änderungen innerhalb privater Transaktions-Puffer vorgenommen, so daß schmutzige Änderungen nicht sichtbar sind.
Aufgabe 8-4 Vergleich von Synchronisationsverfahren
-
| a) Rücksetzung von T1; | | T2 < T3 |
| b) Rücksetzung von T2; | | T3 < T1 |
| c) Rücksetzung von T1 oder T2; | | T3 < T2 oder T3 < T1 |
| d) Wait (T1), Die (T2); | | T3 < T1 |
| e) Wound (T3), Wait (T2); | | T1 < T2 |
| f) Wait (T1), Wait (T2); | | T3 < T1 < T2 |
| g) keine Blockierung/Rücksetzung; | | T2 < T3 < T1 |
Aufgabe 8-5 Deadlock-Erkennung
- Lokale Wartegraphen (EXT = EXTERNAL):
- R1: EXT -> T2 -> T1 -> EXT
R2: EXT -> T1 -> T3 -> EXT
R3: EXT -> T3 -> T2 -> EXT
- R2 sendet keine Nachricht, da ts (T1) < ts (T3)
- Nachricht von R1 nach R2: EXT -> T2 -> T1 -> EXT
- Vervollständigung in R2 zu EXT -> T2 -> T1 -> T3 -> EXT;
keine Folgeaktion, da ts (T2) < ts (T3)
- Nachricht von R3 nach R1: EXT -> T3 -> T2 -> EXT
- Vervollständigung in R1 zu EXT -> T3 -> T2 -> T1 -> EXT
Nachricht von R1 an R2,
- Vervollständigung ergibt T3 -> T2 -> T1 -> T3
Erkennung des Deadlocks in R2 (=> Rücksetzung der lokalen Transaktion T2)
- Deadlock wurde mit 3 Nachrichten aufgelöst
(2 Nachrichten, falls erste Nachricht von R1 nach R2 nicht gesendet wird)
Aufgabe 9-1: Netzwerk-Partitionierungen
- ROWA und Write-All-Available erlauben keine weiteren Änderungen nach einer Netzwerk-Partitionierung, Lesezugriffe sind jedoch auf allen Kopien weiterhin möglich. Beim Primary-Copy-Verfahren kann die Verarbeitung in der Partition mit dem Primärkopien-Rechner fortgeführt werden. Bei Voting-Verfahren können in höchstens einer Partition Änderungen fortgeführt werden, sofern noch ein ausreichendes Schreib-Quorum erreichbar ist. Ein Lesen ist möglich in allen Partitionen, in denen noch ein Lese-Quorum gebildet werden kann (falls noch ein Schreiben möglich ist, kann in keiner anderen Partition ein Lese-Quorum erreicht werden).
Aufgabe 9-2 Datenbankverteilung
- Mit dem ROWA-Protokoll kostet ein Lesezugriff auf eine lokale Kopie keine Nachrichten, für einen nicht-lokalen Lesezugriff fallen 4 Nachrichten an (2 für den eigentlichen Zugriff mit Sperrerwerb, 2 zur Sperrfreigabe). Jede Änderung erfordert pro externer Kopie 6 Nachrichten (2 zur Sperranforderung, 4 zur Commit-Behandlung).
Im Beispiel sollte Objekt A an R2 gespeichert werden, da dort die meisten Zugriffe erfolgen. An Rechner R4 ist eine Speicherung von A nicht sinnvoll, da damit nur 80 Nachr./s eingespart würden; die insgesamt 30 Änderungen/s würden jedoch 180 Nachr./s zum Sperren/Aktualisieren der Kopie erfordern. Diese Änderungskosten entstehen auch bei einer Speicherung von A an Rechner R3 an. Dort betragen jedoch die Einsparungen für Lesezugriffe 200 Nachr./s, so daß A an R3 gespeichert werden sollte. Eine Kopie an Rechner R1 würde 120 Nachr./s aufgrund der 20 externen Änderungen/s verursachen. Die Einsparungen für Lesezugriffe an R1 betragen ebenfalls 120 Nachr./s, so daß eine Speicherung von A an R1 vetretbar ist.
Aufgabe 9-3 Kommunikationsaufwand (ROWA, Primary-Copy)
- Nachrichtenbedarf ROWA
- Die Lesezugriffe sind alle lokal bis auf Rechner R4. Setzt man pro Lesezugriff 4 Nachrichten an (2 für Objektzugriff, 2 für Sperrfreigabe), so entstehen dort 80 Nachr./s.
- Für jede Änderung in R1 bzw. R2 sind die Schreibsperren bei jeweils zwei anderen Rechnern anzufordern (je 2 Nachr.), die auch ins Commit-Protokoll einzubeziehen sind (je 4 Nachr.). Dies erfordert insgesamt (10 + 20) * (2*2 + 2*4) = 360 Nachr./s.
- Der Gesamtaufwand für ROWA beträgt somit 440 Nachr./s.
- Primary-Copy
- Rechner R2 sei der Primärkopien-Rechner. Kommunikation entsteht somit nur für die Zugriffe in den anderen Rechnern.
- Für die Änderungszugriffe in R1 fallen 10*(2+4) = 60 Nachr./s für die Kommunikation mit R2 an. Für die Lesezugriffe in R4 entstehen wieder 80 Nachr./s; die Lesezugriffe in R1 und R3 sind lokal, wenn auf Konsistenz verzichtet wird, anderenfalls ist eine Interaktion mit dem Primary-Copy-Rechner R2 erforderlich (Sperrerwerb bzw. Objektzugriff). Dafür fallen (30 +50) * (2 + 2) = 320 Nachr./s an.
Daneben verursacht noch das asynchrone Ändern der Kopien durch den Primary-Copy-Rechner Kommunikationsaufwand. Die Änderungen von R1 sind zusätzlich an R3 zu propagieren, die von R2 an R1 und R3. Setzt man pro Änderung jeweils 2 Nachrichten an, ergeben sich 10*2 + 20*2*2 = 100 Nachr./s.
- Der Gesamtaufwand für Primary-Copy-Verfahren beträgt somit 560 Nachr./s (bzw. 240 Nachr./s bei inkonsistentem Lesen), wobei 100 Nachr./s asynchron abgewickelt werden.
Aufgabe 9-4 Voting-Verfahren
- T1: P1; T2: P2; T3: -
- T4 könnte für die gegebene Partitionierung weiterhin bearbeitet werden, indem man R1 oder R3 (welche Kopien von A und B halten) eine für Änderungen ausreichende Stimmenzahl zuordnet. Eine Möglichkeit wäre die für A vorliegenden Stimmen (<2, -, 1> und Quoren (r=2, w=2) beizubehalten und für B die Stimmenverteilung <3, 1, 1> sowie w=3, r=3 zu wählen. In diesem Fall könnte T4 lokal auf R1 (also in Partition P1) ausgeführt werden.
Aufgabe 9-5 Katastrophen-Recovery
- Systemkonfigurationen zur Katastrophen-Recovery: Beschränkung auf zwei Knoten (Rechenzentren); meist geringe Nutzung der Backup-Kopie im Normalbetrieb; keine Unterstützung für Netzwerk-Partitionierungen; effizientere Propagierung von Änderungen; keine Synchronisation auf Backup-Kopie; neben Daten sind im Backup-System auch Anwendungen sowie Netzwerkverbindungen repliziert.
- Unterschiede zur Schnappschuß-Replikation: Hauptziel hohe Verfügbarkeit; meist Führen einer vollständigen DB-Kopie anstatt benutzerspezifischer Teilmengen; Backup-Kopie meist nahezu aktuell, während bei Schnappschüssen benutzerdefinierte Aktualisierungsintervalle bestehen
Aufgabe 11-1: Beschränkung globaler Änderungstransaktionen
- a) Ohne globales Commit-Protokoll erfolgt am Ende jeder lokalen Sub-Transaktion ein Commit mit Sperrfreigabe. Damit ist z.B. folgender, nicht serialisierbare Ablauf für zwei globale Transaktionen GT1 und GT2 möglich (ci = lokales Commit einer Sub-Transaktion von GTi):
- LDBS1: r1 (x), c1, w2 (x), c2 (GT1 < GT2)
LDBS2: r2 (y), c2, w1 (y), c1 (GT2 < GT1)
- b) ja
Aufgabe 11-2 Gateway-Anzahl
- a) 10*5 = 50, b) 10+5 = 15, c) 5
Aufgabe 11-3 Abruf großer Ergebnismengen
- Der satzweise Transport der Ergebnismenge kann durch gebündelte Übertragung und Pufferung mehrerer Sätze bzw. des gesamten Ergebnisses auf Client-Seite vermieden werden. Dies setzt dort jedoch zumindest eine begrenzte DBVS-Funktionalität zur Pufferung und Cursor-Verwaltung voraus, insbesondere um einzelne Satzanforderungen (FETCH-Aufrufe) zu bearbeiten. Dies läßt sich in homogenen Umgebungen (Tools und DBVS eines Herstellers) am einfachsten realisieren und wird auch von verschiedenen Produkten bereits unterstützt ("Block Fetch"). Im heterogenen Fall könnten DB-Gateways eine ähnliche Funktionalität unterstützen, sofern sie auf Client-Seite ausgeführt werden. Eine Alternative wäre eine neue Systemkomponente auf Client-Seite für Pufferung und Cursor-Verwaltung anzubieten, die dann mit den einzelnen DBVS bzw. Gateways auf Server-Seite kommuniziert.
Aufgabe 12-1: Schemaarchitektur eines lose gekoppelten FDBS
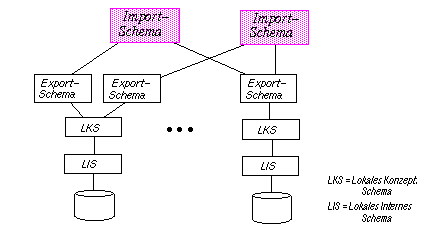
Aufgabe 12-2 Semantische Heterogenität
- Namenskonflikt: Synonyme PNAME und BNAME
- Struktureller Konflikt: unterschiedliche Repräsentation von Adressen (einfaches Attribut ANSCHRIFT vs. drei Attributen)
- Integritätsbedingungen: unterschiedliche Primärschlüssel (PNR bzw. BNR), die unabhängig voneinander vergeben werden; unterschiedliche Datentypen für PNAME und BNAME (40 vs. 50 Zeichen maximale Länge) sowie für Adressattribute
Aufgabe 12-3 Schemaintegration
-
Relation PERSON ( PNR INTEGER, {Personalnummer}
BNR INTEGER, {Benutzernummer, optional}
NAME CHAR (50),
WOHNORT CHAR (30),
PLZ INTEGER,
STRASSE CHAR (30),  )
)
- Für Bibliotheksbenutzer ohne Personalnummer muß diese durch eine eigene Funktion erzeugt werden. Daneben werden Transformationsfunktionen benötigt, um aus dem einfachen Attribut ANSCHRIFT die drei Einzelkomponenten zu extrahieren. Gegebenenfalls ist auch eine Transformation zur Angleichung der Datenrepräsentation für Namen erforderlich.
Aufgabe 12-4 Query-Optimierung in FDBS
- Zur Optimierung stehen prinzipiell nur die Angaben der Export-Schemata zur Verfügung. Ohne Kenntnis des vollständigen DB-Aufbaus, von Angaben der internen Schemata sowie der von den LDBS unterstützten Algorithmen (z.B. zur Join-Berechnung) kann jedoch keine ausreichende Kostenabschätzung verschiedener Ausführungspläne vorgenommen werden. Die Bereitstellung dieser Informationen beeinträchtigt jedoch die Autonomie der LDBS.
Aufgabe 12-5 Quasi-Serialisierbarkeit
- Es liegt keine Serialisierbarkeit vor, da gilt:
- LDBS1: GT1 < LT3 < GT2
LDBS2: GT2 < LT4 < GT1.
- Der Schedule ist jedoch quasi-serialisierbar, da die Konflikte in LDBS1 irrelevant sind und die Sub-Transaktion von GT2 vor der von GT1 ausgeführt wird. Somit besteht in beiden Knoten die quasi-serielle Ausführungsreihenfolge GT2 vor GT1.
Aufgabe 13-1: Abhängigkeiten zwischen Systemfunktionen
- Synchronisation <-> Lastverteilung: Nutzung von Lokalität zur Einsparung von Synchronisationsnachrichten sowie globaler Konflikte; Lokalität durch Lastverteilung zu unterstützen (affinätsbasiertes Routing)
- Synchronisation <-> Crash-Recovery: korrekte Fortführung des Synchronisationsprotokolls im Fehlerfall (Rekonstruktion globaler Sperrtabellen u.ä.); Änderungen während Recovery mit sonstiger Transaktionsverarbeitung zu synchronisieren
- Lastverteilung <-> Crash-Recovery: Umstellung der Routing-Strategie (ausgefallenem Rechner können keine Transaktionen mehr zugewiesen werden; Neustart betroffener Transaktionen auf überlebendem Rechner)
Aufgabe 13-2 GEH-Synchronisation
- Wenigstens je zwei GEH-Zugriffe zum Setzen bzw. Freigeben einer Sperre: Lesen des Sperreintrages; Modifikation im Hauptspeicher, Zurückschreiben in GEH mit Compare&Swap (um sicherzustellen, daß nicht anderer Rechner gleichzeitig denselben Eintrag modifiziert). Bei Verwaltung von Sperreinträgen innerhalb Hash-Tabelle sind ggf. weitere Lesezugriffe aufgrund von Namenskollisionen erforderlich. Doppeltes Führen der Sperrtabelle erfordert nur zweifache Ausführung der Schreibzugriffe (GEH-Zugriffshäufigkeit steigt um maximal 50%)
Aufgabe 14-1: Zentrale Sperrprotokolle
- Aufgrund lokaler Verteilung ist keine Knotenautonomie mehr zu unterstützen; Kommunikation zur Synchronisation für Shared-Disk unabdingbar (bei loser Kopplung), während sie in Verteilten DBS mit verteiltem Sperrprotokoll vermeidbar ist
Aufgabe 14-2 GLM-Ausfall
- Im Extremfall sind alle laufenden Transaktionen abzubrechen, und die Verarbeitung muß mit "leerer" globaler Sperrtabelle auf einem neuen GLM-Rechner beginnen. Das Abbrechen laufender Transaktionen kann umgangen werden, wenn die globale Sperrtabelle aus den Sperrangaben der lokalen Sperrtabellen der Verarbeitungsrechner rekonstruiert wird, was i.a. möglich ist.
Aufgabe 14-3 Dedizierte Sperrverfahren
- größeres Potential zur Nachrichtenbündelung; weniger Nachrichten zur Sperrfreigabe; komplette Sicht auf globale Sperrsituation erleichtert globale Deadlock-Erkennung
Aufgabe 14-4 : Lese- und Schreibautorisierungen
- Sperranforderungen:
- mit Schreibautorisierungen: 22 Nachrichten (Entzug der Schreibautorisierung mit jeweils 4 Nachrichten zu den Zeitpunkten t4, t5, t6, t7 und t8)
- mit Leseautorisierungen: 18 Nachrichten (RA-Entzug zu Zeitpunkt t9: 6 Nachrichten)
- mit Lese- und Schreibautorisierungen: 14 Nachrichten (t4: WA-Entzug mit Konvertierung nach RA für R1; t9: RA-Entzug mit WA-Gewährung für R3)
- Nutzung der Schreibautorisierungen allein ungünstig wegen geringer rechnerspezifischer Lokalität;Wirksamkeit der Leseautorisierungen durch X-Sperren eingeschränkt
- Sperrfreigabe:
- Ohne Autorisierungen: 9 globale Sperrfreigaben (9 Nachrichten)
- Bei Verwendung von Schreibautorisierungen sowie von Lese- und Schreibautorisierungen werden in dem Beispiel keine zusätzlichen Nachrichten zur Sperrfreigabe erforderlich, da Sperren zusammen mit WA-/RA-Entzug freigegeben werden !
- Bei alleiniger Nutzung von Leseautorisierungen sind 3 X-Sperren explizit zurückzugeben (t1, t3, t9)
- Gesamtnachrichtenanzahl:
-
- ohne Autorisierungen: 27 (18 + 9)
- Schreibautorisierungen: 22 (22 + 0)
- Leseautorisierungen: 21 (18 + 3)
- Lese-/Schreibautorisierungen: 14 (14 + 0)
Aufgabe 14-5 Primary-Copy-Sperrverfahren
- ohne Leseautorisierung: 15 (10+5) Nachrichten
5 globale Sperranforderungen
=> 10 Nachrichten zur Sperranforderung, 5 zur Freigabe
- mit Leseautorisierung: 10 (8+2) Nachrichten
t4, t5: RA-Zuweisung an R2 und R3
t9: RA-Entzug (4 Nachrichten)
globale Sperrfreigabe für X-Sperre von R3 (t9)
Aufgabe 14-6 Dynamische GLA-Zuordnung
- Beibehaltung der GLA in Rechner R1: 21 Nachrichten
t1: GLA-Übernahme (2 Nachrichten)
t2, t3, t6: lokal
t4, t7: je 4+1 Nachrichten für Sperranforderung/freigabe (10 Nachrichten)
t5,t8,t9: je 2+1 Nachrichten (9 Nachrichten)
- Schreibautorisierungen im Beispiel nicht sinnvoll, da gute GLA-Nutzung.
Leseautorisierungen sinnvoll (17 statt 21 Nachrichten): lokale Synchronisation für t7 und t8 (Einsparung von 8 Nachrichten); Entzug für t9 kostet 4 zusätzliche Nachrichten
- GLA-Migration im Beispiel weniger sinnvoll, da GLA-Änderung zu den Zeitpunkten t1, t4, t5, t6, t7 und t8 anfällt (Anpassung der Directory-Information, dafür stets lokale Sperrfreigabe). Gesamtaufwand: 20 Nachrichten
Aufgabe 15-1: Seitentransfers
- schnellere Bereitstellung der Seite als bei Seitenaustausch über Platte, da Einlesen im Normalfall entfällt; langsamer als direkter Seitentransfer, dafür einfachere Recovery wie für Seitenaustausch über Platte
Aufgabe 15-2 On-Request-Invalidierung und Autorisierungen
- Die Konzepte sind verträglich, da lokale Autorisierung garantiert, daß seit der Zuweisung durch den GLM die Seite nicht an einem anderen Rechner geändert wurde. Folglich kann keine Pufferinvalidierung für die Seite vorliegen.
Aufgabe 15-3 On-Request-Invalidierung
- a) dediziertes Sperrprotokoll
- X-Anforderung durch R1 (2 Nachrichten);
Plattenzugriff zum Einlesen von B;
X-Freigabe (1 Nachr.): I=0111, PO=R1 (Page-Owner)
- R-Anforderung durch R4 (2 Nachr.)
Seitentransfer R1 -> R4 (2 Nachr.), I = 0110, PO=R1
R-Freigabe (1 Nachr.)
- 3. X-Anforderung durch R2 (2 Nachr.)
Seitentransfer R1 -> R2, I=0010 (2 Nachr.)
X-Freigabe (1 Nachr.): I=1011, PO=R2
=> 13 Nachrichten, davon 2 Seitentransfers; 1 Lese-E/A
b) Primary-Copy-Sperrverfahren
- X-Anforderung durch R1 an GLA-Rechner R2 (2 Nachr.);
Seite B kann mit Sperrgewährung an R1 übertragen werden;
X-Freigabe mit Übergabe der neuen Seitenversion an R2 (1 Nachr.): I=0011
- R-Anforderung durch R4 (2 Nachr.)
Seitentransfer R1 -> R4 kann mit Sperrgewährung kombiniert werden, I = 0010
R-Freigabe (1 Nachr.)
- X-Anforderung durch R2 (lokal)
X-Freigabe (lokal): I=1011
=> 6 Nachrichten, davon 3 Seitentransfers; keine Lese-E/A
Aufgabe 15-4 Haltesperren
-
- X-Anforderung durch R1 an GLM;
RA-Entzug für R2 und R3 mit Eliminierung von Seite B;
Sperrgewährung an R1 (6 Nachrichten); R1: WA, PO=R1
Einlesen von Seite B von Platte
- R-Anforderung durch R4 an GLM;
WA-Entzug für R1 (Konversion nach RA); Seitentransfer R1 -> R4;
RA-Gewährung an R4 (5 Nachrichten); R1, R4: RA, PO=R1
- X-Anforderung durch R2, RA-Entzug für R1 und R4;
Seitentransfer R1 -> R2; WA-Gewährung an R2 (7 Nachrichten); R2: WA; PO=R2
=> 18 Nachrichten, davon 2 Seitentransfers; 1 Lese-E/A
- sehr hohe Nachrichtenanzahl durch RA/WA-Entzug; Haltesperren erlauben im Beispiel keine lokale Sperrvergabe
Aufgabe 15-5 Kohärenzkontrolle bei dynamischer GLA-Zuordnung
- Nach Kap. 15.6 empfiehlt sich eine On-Request-Invalidierung mit dynamischer Page-Owner-Zuordnung. Kommunikationseinsparungen sind möglich, wenn der GLM-Rechner einer Seite auch die Page-Owner-Funktion wahrnimmt. Dies erfordert eine Migration der GLA an den Rechner, wo eine Seite geändert wird. Damit können Seitenanforderungen stets mit Sperranforderungen kombiniert werden, und Seiten werden mit der Sperrgewährung bereitgestellt. Dafür sind die Angaben zur GLM-Lokalisierung häufig anzupassen.
Aufgabe 15-6 Kohärenzkontrolle in Workstation/Server-DBS
- Der Server-Rechner fungiert als GLM-Rechner sowie zentraler Page-Owner für die gesamte Datenbank, so daß Sperr- und Seitenanforderungen stets kombiniert werden. Zudem erfolgt die Übertragung von Änderungen zum Server zusammen mit der Sperrfreigabe. Zur Behandlung von Pufferinvalidierungen kommt sowohl eine On-Request-Invalidierung als auch der Einsatz von Haltesperren in Betracht. Damit sind folgende Verfahrenskombinationen als sinnvoll zu erachten: S1 + P3/P4 + U2.
- Lese/Schreibautorisierungen erlauben Kommunikationseinsparungen, da sie eine lokale Sperrvergabe in den Workstations gestatten und die Gültigkeit lokaler Seitenkopien garantieren (auch bei On-Request-Invalidierung). Damit wird auch die Anzahl von Seitentransfers zum Server reduziert, da erst beim Entzug einer Schreibautorisierung eine Übertragung notwendig ist. Bei entsprechender Lokalität können somit viele Änderungen vor einer Übertragung akkumuliert werden. Der Seitentransfer erfolgt zudem asynchron bezüglich der ändernden Transaktionen (die Log-Daten sind jedoch aus Sicherheitsgründen beim Commit zum Server zu transferieren).
- Hierarchische Sperren erlauben weitergehende Kommunikationseinsparungen, vor allem wenn beim Sperrerwerb zugleich große Datenmengen in die Workstation gebracht werden.
Aufgabe 15-7 Kohärenzkontrolle bei der Katalogverwaltung
- SDD-1: Multicast-Invalidierung; R*: On-Request-Invalidierung
Aufgabe 16-1: Antwortzeit-Speedup
-
|
100-MIPS-Prozessor: | | AZ = 10 (CPU) + 50 (E/A) = 60 ms; Speedup = 150/60 = 2.5
E/A verhindert linearen Speedup (Amdahls Gesetz) ! |
| 10*10 MIPS: | | AZ = 10 (CPU) + 5 (E/A) + 0.15 (Komm.) = 15,15 ms; Speedup = 9.9
(linearer Speedup) |
| 100*1 MIPS: | | AZ = 10 + 0.5 + 1.05 = 11.55 ms; Speedup = 13
(besser als 10*10 MIPS, da weniger E/A pro Rechner) |
Aufgabe 16-2 Parallelisierung von Transaktionsprogrammen
- Zerlegung in vier parallele Teilprogramme mit Zugriffen auf ACCOUNT (2 Operationen), TELLER, BRANCH und HISTORY.
Aufgabe 17-1: Bestimmung des Verteilgrades
- Es gilt popt = SQRT (c * K / b)
- Relationen-Scan: K = 107
- popt = SQRT (5*10-5 * 107 / 5*10-3 )= SQRT (105) = 316 > N = 100
- => popt = 100
- Index-Scan (1%): K = 105
- popt = SQRT (5*10-5 * 105 / 5*10-3 )= SQRT (103) = 31,6
- Gewichtetes Mittel: D = 0,3*100 + 0,7*31,6 = 52
Aufgabe 17-2 Verteilattribut
- hohe Zugriffshäufigkeit; meist hoher Anteil von Exact-Match-Anfragen, die dann mit minimalem Kommunikationsaufwand (1 Rechner) bearbeitbar sind
Aufgabe 17-3 Verteilinformationen in Indexstrukturen
- Ein Problem liegt in der Speicherung dieser erweiterten Indexstruktur selbst. Bei vollkommener Replikation ensteht ein sehr hoher Änderungsaufwand, da jede Einfüge- und Löschoperation auf der Relation sowie Änderungen bezüglich des indizierten Attributs auf allen Kopien anzuwenden sind. Bei zentralisierter oder partitionierter Speicherung fallen zusätzliche Kommunikationsverzögerungen für den Indexzugriff an. Generell ist daneben mit zusätzlichen E/A-Operationen zu rechnen, da der Index im Gegensatz zur Fragmentierungsinformation i.a. nicht im Hauptspeicher gehalten werden kann. Für Sekundärschlüssel, bei denen einzelne Attributwerte mehrfach vorkommen, können zudem einzelne Attributwerte über viele Knoten verteilt gespeichert sein, zumal die Datenverteilung hinsichtlich der Werteverteilung eines anderen Attributs erfolgte. Somit muß die Anfrage ggf. dennoch auf einem Großteil der Rechner verarbeitet werden.
Aufgabe 17-4 Verstreute Replikation
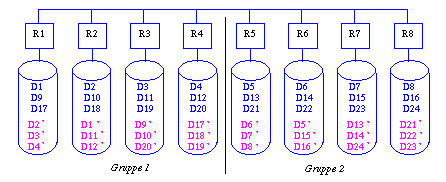
Aufgabe 17-5 Verkettete Replikation
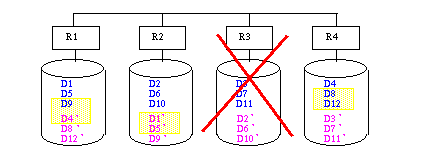
- Die unterlegten Bereiche, werden nach Ausfall von R3 nicht genutzt..Jeder Rechner verwaltet damit 4 Bereiche.
Aufgabe 18-1: Parallele Join-Berechnung
- R: 1 Mill.
 100 B = 100 MB; S: 100.000
100 B = 100 MB; S: 100.000  100 B = 10 MB
100 B = 10 MB
- Dynamische Replikation (Verschicken der S-Relation an alle R-Knoten):
- 10 MB
 4 = 40 MB
4 = 40 MB
Dynamische Partitionierung (Umverteilung von R und S):
- 100 + 10 MB = 110 MB
Dynamische Partitionierung ohne Umverteilung von S: 100 MB
- Die dynamische Replikation verursacht in diesem Beispiel den geringsten Kommunikationsumfang !
Aufgabe 18-2 Mindest-Hauptspeichergröße für partitionierten Hash-Join
- Für q Partitionen werden zur Partitionierung wenigstens q+1 Seiten im Hauptspeicher benötigt (1 Eingabepuffer, q Ausgabepuffer). Für die Hash-Tabelle jeder S-Partition werden wenigstens b/q Seiten notwendig. Setzt man q=b/q, ergibt sich q=
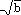 , so daß der minimale Hauptspeicherumfang
, so daß der minimale Hauptspeicherumfang 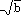 + 1 Seiten beträgt.
+ 1 Seiten beträgt.
Aufgabe 18-3 TID-Hash-Join
- Der TID-Hash-Join zahlt sich vor allem aus, wenn damit die E/A-Vorgänge zur Überlaufbehandlung vollkommen umgangen werden. Die Einsparungen sind bei kurzen Join-Attributen bzw. langen Sätzen am höchsten (Bsp.: Komprimierung der Hash-Tabelle um Faktor 10 für Satzlänge 100 B gegenüber Schlüssel+TID von 10 B). Nachteilig ist, daß eine Nachbearbeitung notwendig wird, um die im Verbundergebnis enthaltenen Tupel der kleineren Relation über die TIDs zu rekonstruieren. Der Aufwand für die damit verbundenen Externspeicherzugriffe ist umso höher, je mehr Tupel sich qualifizieren. Im verteilten Fall (Shared-Nothing) ist der Ansatz weniger attraktiv, da bei einer Join-Berechnung außerhalb der Datenknoten keine direkte Auflösung von TID-Verweisen möglich ist (-> Kommunikation).
Aufgabe 18-4 Paralleler Hash-Join/Überlaufbehandlung an Datenknoten
- Paralleles Lesen und Partitionieren von S
an jedem S-Knoten j (j=1 .. m) führe parallel durch:
lies lokale S-Partition Sj und partitioniere sie in q Sub-Partitionen zur Überlaufbehandlung Sj1 bis Sjq durch Anwendung einer Partitionierungsfunktion g auf dem Join-Attribut
- Paralleles Lesen und Partitionieren von R
an jedem R-Knoten i (i=1..n) führe parallel durch:
lies lokale R-Partition Ri und partitioniere sie in q Sub-Partitionen Ri1 bis Riq (Partitionierungsfunktion g)
- Parallele Umverteilung und Join-Berechnung
für l = 1, 2 bis q führe nacheinander aus:
- an jedem S-Knoten j (j=1 .. m) lies Sub-Partition Sjl und sende jedes S-Tupel an
zuständigen Join-Rechner (Verteilungsfunktion f)
- in jedem Join-Knoten k (k=1...p) füge eingehende S-Tupel in Hash-Tabelle ein
- an jedem R-Knoten i (i=1 .. m) lies Sub-Partition Ril und sende jedes R-Tupel an
zuständigen Join-Rechner (Verteilungsfunktion f)
- in jedem Join-Knoten k (k=1...p) überprüfe Hash-Tabelle für eingehende R-Tupel
und bilde das Join-Ergebnis
Aufgabe 18-5 Paralleler Hash-Join bei Shared-Everything
- Voraussetzung für die Nutzung von Datenparallelität ist auch bei SE die verteilte Speicherung der Eingaberelationen sowie ggf. temporärer Dateien auf mehreren Platten. Weiterhin muß eine Aufteilung des gemeinsamen Hauptspeichers in mehrere Bereiche erfolgen, in denen parallel die Join-Berechnung durch unterschiedliche Join-Prozesse erfolgen kann. Das Einlesen der ersten Relation erfolgt parallel durch mehrere Leseprozesse, wobei jeder Prozeß auf disjunkte Plattenmengen zugreift. Die eingelesenen Tupel werden dann - ggf. durch separate Prozesse - in die zugehörige Hash-Tabelle eingetragen, wobei eine Synchronisation (über Semaphore) notwendig wird. Das Lesen der zweiten Relation erfolgt analog, wobei die Join-Berechnung nur Lesezugriffe auf die Hash-Tabellen und somit keine Synchronisation erfordert. Die Join-Ergebnisse werden durch spezielle Schreibprozesse (asynchron) geschrieben. Der Datenaustausch zwischen Lese-, Join- und Schreibprozessen erfordert synchronisierte Zugriffe auf gemeinsame Pufferbereiche; dafür entfällt der Kommunikations-Overhead zur Datenumverteilung von SN-Systemen.
Aufgabe 18-6 Daten-Skew
- Hash-Funktion führt zu Umverteilungs- und Join-Produkt-Skew. Das Join-Ergebnis von rund 100.000 Tupeln ist gleichmäßig von 5 Prozessoren zu generieren. Hierzu kann eine überlappende Bereichsfragmentierung gewählt werden, mit 2 bzw. 3 Partitionen für Wert 1 bzw. 2, wobei jede der 5 Partitionen einem anderen Prozessor zugewiesen wird. Die restlichen Werte können daneben gleichmäßig 5 weiteren Bereichen zugeteilt werden (z.B., 3-202, 203-402, 403-601, 602-801, 802-1000), die von jeweils einem der Join-Prozessoren zu bearbeiten sind.
Aufgabe 18-7 Parallele Änderungstransaktionen bei Shared-Disk
- Parallele Teiltransaktionen verschiedener Rechner können dieselben Daten referenzieren und ändern, so daß eine Synchronisation zwischen Teiltransaktionen erforderlich ist (z.B. im Rahmen eines geschachtelten Transaktionskonzepts). Ebenso ist die Kohärenzkontrolle zu erweitern, um Änderungen zwischen Teiltransaktionen auszutauschen. Die verteilte Transaktionsausführung mit Änderungen an verschiedenen Rechnern verlangt zudem ein verteiltes Commit-Protokoll.