




6 Verteilte Anfragebearbeitung
Der erste Schritt der Anfragetransformation überführt DB-Operationen einer deskriptiven Anfragesprache wie SQL in eine interne Darstellung. Wir nehmen an, daß hierzu eine Transformation in einen äquivalenten Ausdruck der Relationenalgebra erfolgt. Diese Aufgabe kann weitgehend wie in zentralisierten DBS durchgeführt werden, da sich die Anfragen auf Objekte des globalen konzeptionellen Schemas (GKS) beziehen und noch keine Verteilungsinformation verwendet wird (für Katalogzugriffe kann jedoch Kommunikation erforderlich werden). Die Anfragezerlegung selbst unterteilt sich wiederum in mehrere Teilschritte wie Syntaxanalyse (Parsing), Namensauflösung, semantische Analyse und Normalisierung. Weiterhin können bereits algebraische Optimierungen zur Vereinfachung und Restrukturierung des relationalen Ausdrucks vorgenommen werden. Damit lassen sich schon vorab einige Ausführungspläne mit hohen Kosten ausschließen.
Der zweite Schritt der Daten-Lokalisierung verwendet die Angaben des globalen Verteilungsschemas, um die Knoten zu bestimmen, an denen sich Fragmente der zu referenzierenden Relationen befinden. Der im ersten Schritt erzeugte algebraische Ausdruck wird dazu in einen sogenannten Fragment-Ausdruck (Fragment-Anfrage) transformiert. Dabei wird für globale Relationen der jeweilige relationale Ausdruck zur Rekonstruktion der Relation aus ihren Fragmenten eingesetzt. Auf dem derart erzeugten Ausdruck werden wiederum algebraische Optimierungen zur Vereinfachung und zur effizienten Rekonstruktion angewendet.
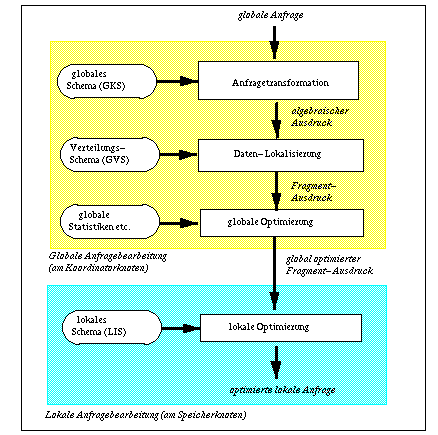
Schließlich kann jeder Knoten, der an der Anfrage beteiligt ist, die ihm zugeordnete Teilanfrage lokal optimieren (lokale Optimierung), wobei z.B. der Ausführungsalgorithmus für bestimmte Operatoren festgelegt wird. Dies kann wie in zentralisierten DBS unter Einsatz lokaler Katalogdaten erfolgen. Die Aufgabenverteilung zwischen globaler und lokaler Optimierung hängt wesentlich von der Verteilung der Katalogdaten ab, z.B. ob Angaben des internen Schemas wie Indexstrukturen global oder nur lokal bekannt sind. Nach Abschluß der Optimierung erfolgt noch die Code-Generierung für den ermittelten Ausführungsplan, d.h. die Erstellung eines ausführbaren Programmes. Dabei wird üblicherweise für jede lokale Teilanfrage ein Ausführungsmodul erstellt und an dem jeweiligen Knoten gespeichert.
Zur Realisierung der angesprochenen Schritte kommen prinzipiell ein Übersetzungs- oder ein Interpretationsansatz in Betracht. Beim Übersetzungsansatz werden Erstellung eines Ausführungsplanes sowie Ausführung desselben in zeitlich getrennten Schritten vorgenommen. Dies empfiehlt sich vor allem für in Anwendungsprogramme eingebettete DB-Operationen, für die bereits zur Übersetzungszeit des Programms die Ausführungspläne erstellt werden können. Damit geht der meist hohe Aufwand zur Query-Optimierung nicht in die Ausführungszeiten ein, und der Aufwand fällt auch bei wiederholter Ausführung des Programmes bzw. von DB-Operationen (z.B. innerhalb von Programmschleifen) nur einmal an. Allerdings muß gegebenenfalls eine Neubestimmung von Ausführungsplänen veranlaßt werden, wenn zwischenzeitlich relevante Änderungen in den Schemaangaben erfolgten (z.B. Änderungen im konzeptionellen Schema, bezüglich Datenverteilung oder Indexstrukturen).
Beim Interpretationsansatz erfolgt dagegen die Festlegung der Auswertungsstrategie zum Ausführungszeitpunkt, wie es z.B. für Ad-hoc-Anfragen erforderlich ist. Der Hauptvorteil liegt darin, daß dynamische Kontrollentscheidungen möglich sind, basierend auf dem aktuellen Verarbeitungszustand (z.B. Größe von Zwischenergebnissen, Systemauslastung). Allerdings sind die Bearbeitungszeiten für komplexere Anfragen insgesamt wesentlich höher als beim Übersetzungsansatz, wenn erst während der Ausführung die Verarbeitungsstrategie für einzelne Teilschritte festgelegt wird. Daher wird selbst für Ad-hoc-Anfragen empfohlen, zunächst einen Ausführungsplan gemäß dem Übersetzungsansatz zu bestimmen und diesen direkt anschließend auszuführen [Hä87]. Eine Zwischenform bildet ein hybrider Optimierungsansatz. Dabei erfolgt eine statische Festlegung eines Ausführungsplanes nach dem Übersetzungsansatz, jedoch wird für bestimmte Kontrollentscheidungen eine dynamische Einflußnahme zur Laufzeit vorgesehen.
Im folgenden werden die drei Phasen der globalen Anfragebearbeitung genauer vorgestellt.