




6.5 Bearbeitung von Join-Anfragen
Der Bitvektor B sei folgendermaßen definiert:
Zur Abbildung der Verbundattributwerte wird eine Hash-Funktion h verwendet, die jeden Attributwert eindeutig auf eine ganze Zahl zwischen 1 und n abbildet. Für jeden Verbundattributwert wird das derart zugeordnete Bit im Bitvektor gesetzt. Als Verbundpartner werden alle Tupel ermittelt, für deren Verbundattributwert das Bit gesetzt ist. Die Join-Berechnung R 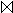 S läuft demnach in folgenden Schritten ab (im Bitvektor B seien anfangs alle Bits zurückgesetzt):
S läuft demnach in folgenden Schritten ab (im Bitvektor B seien anfangs alle Bits zurückgesetzt):
 V (R) setze zugehöriges Bit B (h(v));
V (R) setze zugehöriges Bit B (h(v));
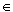 S | B ( h(s.v)) gesetzt} und Übertragung an KR
S | B ( h(s.v)) gesetzt} und Übertragung an KR
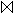 Z = R
Z = R 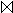 S.
S.
Die Einsparungen im Übertragungsvolumen durch Verwendung eines Bitvektors sind natürlich um so höher, je länger die Verbundattributwerte sind oder je mehr unterschiedliche Werte ansonsten zu übertragen wären. Ein weiterer Vorteil liegt darin, daß die Bestimmung der Verbundpartner in Schritt 2 sehr einfach wird. Hierzu ist kein Join durchzuführen, sondern es genügt das Lesen der Relation (Scan) in einer beliebigen Reihenfolge. Insbesondere dieser Aspekt ergab in Performance-Abschätzungen signifikant bessere Resultate für Bitvektor-Joins verglichen mit allgemeinen Semi-Join-Methoden [ML86].
Auf der anderen Seite ist die Hash-Abbildung i.a. nicht injektiv, so daß mit dem Bitvektor nur potentielle Verbundpartner bestimmt werden. Es qualifizieren sich dabei jedoch auch Tupel, die im Verbundergebnis nicht beteiligt sind. Die Übertragung solcher Tupel führt dazu, daß die durch den Bitvektor erreichten Einsparungen zumindest teilweise wieder zunichte gemacht werden. Das Ausmaß dieser Effekte hängt neben der Verteilung der Verbundattributwerte v.a. von der Länge des Bitvektors n und der Hash-Funktion h ab. Durch Wahl eines ausreichend großen n und geeigneter Hash-Funktionen kann die Filterwirkung jedoch meist sehr gut gehalten werden. Diese Problematik wurde bereits in anderen Kontexten untersucht, wo solche Hash-Filter (auch Bloom-Filter genannt) anwendbar sind [Bl70, SL76].
Beispiel 6-11