



Wegen der komplexen Datenstrukturen und Beziehungen sowie der zugeschnittenen Operationen kann keine allgemeingültige Lösung im Sinne unserer mengenorientierten DB-Schnittstelle (Datenmodellschnittstelle in Abb. 1.8) erwartet werden. Deshalb wurden erweiterte DBS-Architekturen entwickelt, bei denen die gewünschte anwendungsspezifische DBS-Funktionalität durch Zusatzschichten bereitgestellt wurde [HÄRD87a, PAUL87]. Wegen der starken Differenzierung dieser Funktionalität mußte pro Anwendungsbereich eine separate Zusatzschicht (Modellabbildung) entwickelt werden, deren Dienste dem Benutzer an der Anwendungsschnittstelle angeboten werden. Außerdem erzwangen die interaktive Systemnutzung, die häufige Ausführung berechnungsintensiver Funktionen sowie die aus Leistungsgründen erforderliche Nutzung von Referenzlokalität auf den Daten die Verfügbarkeit solcher Zusatzschichten "in der Nähe der Anwendung", was ihre client-seitige Zuordnung (in einer Workstation) begründet.
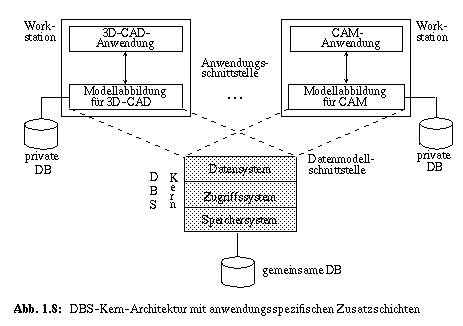
In Abb. 1.8 ist eine solche Grobarchitektur mit einem allgemein einsetzbaren DBS-Kern-System skizziert. Insbesondere ergeben sich bei der Realisierung solcher DBS-Erweiterungen client-seitig spezielle Probleme, deren Lösung hier nicht weiterverfolgt werden kann. Vertiefende Darstellungen sind in der aktuellen Literatur zur Architektur von DBS-Erweiterungen für Non-Standard-Anwendungen veröffentlicht [CARE86b, DADA86, HAAS90, HÄRD88, HÜBE92, MITS88].
Im Gegensatz zu den DBS, die klassische Datenmodelle realisieren, wollen objektorientierte DBS einen nahtlosen Übergang und eine stärkere Verzahnung zu/mit dem Anwendungsprogramm erzielen. OODBS besitzen in der Regel satzorientierte DB-Schnittstellen als API, mit denen die Anwendung direkt und typischerweise navigierend Bezug auf die DBS-Datenstrukturen nehmen kann. Ein nahtloser Übergang zur Anwendung wird vor allem dadurch ermöglicht, daß das Typsystem eines OODBS mit dem der eingesetzten Programmiersprache übereinstimmt und daß die Anwendung in einem anwendungsnahen Objektpuffer direkt Objekte durchsuchen und manipulieren kann. Deshalb muß die DBS-seitige Verwaltung auf Client/Server-Architekturen ausgelegt sein,[9] wobei in komplexen Anwendungen häufig leistungsfähige Workstations als Client-Rechner herangezogen werden.
DB-gestützte Client/Server-Architekturen, die vorwiegend für Non-Standard-Anwendungen eingesetzt werden, lassen sich danach unterscheiden, wie die Datenversorgung und damit maßgeblich die Aufgabenverteilung zwischen Client und Server organisiert ist [HÄRD95]. Die drei wichtigsten Grundformen (Page-Server Object-Server und Query-Server) sind in Abb. 1.9 veranschaulicht. Oft wird zusätzlich der File-Server-Ansatz (z. B. mit NFS) als eigenständiger Architekturtyp diskutiert. Dieser läßt sich als spezieller Page-Server auffassen, der NFS als Transportmechanismus für die zu übertragenden Seiten benutzt. Solche File-Server weisen allerdings ein schlechteres Leistungsverhalten auf, da sie i. allg. weder lokal und noch an die typischen Verarbeitungscharakteristika angepaßt sind [DEWI90].
Wie Abb. 1.9 zeigt, stellt jeder Architekturansatz durch den Object-Manager den verschiedenen Anwendungen die gleiche navigierende und objektorientierte Schnittstelle zur Verfügung. Die gezeigten Server-Typen besitzen als minimale Funktionalität ein Speichersystem zur Verwaltung von Dateien auf Externspeicher (DB) und einen Seitenpuffer zur Minimierung der physischen Ein/Ausgabe auf die DB. Weiterhin muß der Server als zentrale Komponente die Synchronisation der client-seitigen DB-Anforderungen übernehmen, was bei langen Entwurfstransaktionen mit Hilfe von persistenten Datenstrukturen (persistente Sperren) zu geschehen hat. Vorsorgemaßnahmen für DB-Fehler und Server-Crash (Logging) und die Behandlung dieser Situationen (Recovery) gehören ebenfalls zu den zentralen Aufgaben. In Anlehnung an die Originalliteratur [DEWI90] erhalten die einzelnen Architekturtypen ihren Namen vom Granulat der Datenanforderung durch den Client.
Beim Page-Server wird jede Seitenanforderung client-seitig durch eine Fehlseitenbedingung (Page-Fault) ausgelöst; daraufhin wird die betreffende Seite vom Server zur Verfügung gestellt. Der Server hat dabei keine Kenntnis des Objektbegriffs: er verwaltet nur Seiten, die (normalerweise) auch das Granulat der Synchronisation und des Logging darstellen. Die Pufferung der Objekte in der Workstation kann nur über die Pufferung der zugehörigen Seiten geschehen, in denen auch die DB-bezogene Verarbeitung (Object-Manager) stattfindet. Alle objektbezogenen Zugriffe und Auswertungen erfolgen demnach in einem client-seitigen Puffer und mit Hilfe eines entsprechenden Zugriffssystems (Abbildung von Objekten auf Seiten).
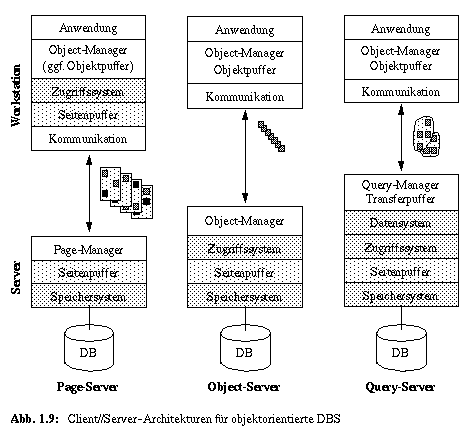
Ein Object-Server liefert in der Grundform auf Anforderung (über eine OID) ein einzelnes Objekt. Erweiterungen dieses Ansatzes erlauben eingeschränkte Anfragemöglichkeiten über inhaltsorientierte Suche mit Hilfe einfacher Suchausdrücke (SSA: simple search arguments), die man auch als "1-mengenorientiert" [NINK98] bezeichnet. Auch bei diesen erweiterten Anforderungsmöglichkeiten wird ein objektweiser Transfer zur Workstation unterstellt. Die übertragenen Objekte können in den Objektpuffer so eingelagert werden, daß ihre Speicherungs- und Zugriffsstrukturen an die Bedürfnisse der navigierenden Anwendung angepaßt sind. Workstation wie auch Server kennen "Objekte", besitzen die entsprechende Verarbeitungsfunktionalität und sind in der Lage, objektbezogene Manipulationen und Auswertungen (Selektion, Projektion, Methoden) durchzuführen. Im Gegensatz zum Page-Server kann hier (wie auch beim nachfolgend beschriebenen Query-Server) das Objekt sowohl als Synchronisations- als auch als Logging-Granulat herangezogen werden.
Query-Server beliefern die Anwendung auf eine "n-mengenorientierte" Anfrage hin mit einer Menge von (komplexen) Objekten, die auf einmal übertragen und auf die Verarbeitungsanforderungen zugeschnitten im Objektpuffer gespeichert wird. Voraussetzung ist eine mächtige Anfrageschnittstelle, die der Object-Manager der Anwendung verfügbar macht. Die Verarbeitung im Objektpuffer geschieht dann über eine navigierende Schnittstelle.
Abb. 1.9 veranschaulicht die Nutzung unseres Schichtenmodells in allen drei Architekturtypen. Im Prinzip wird die Schichtenarchitektur vertikal über Client und Server verteilt. Deshalb sind für die Abwicklung von Client-Anforderungen und für die Ergebnisübertragung zusätzlich client-seitig Kommunikationskomponenten und server-seitig Page-, Object-, oder Query-Manager vorgesehen. Im Gegensatz zur Schichtenmodelldarstellung nach Abb. 1.4 wird beim Speichersystem der server-seitige Seitenpuffer explizit dargestellt, um deutlich zu machen, daß die zu verarbeitenden Daten mehrfach kopiert und client-seitig in Seiten- und Objektpuffern gehalten werden. Beim Page-Server ist das Zugriffssystem client-seitig angesiedelt, da auch die Objektauswahl im Client erfolgt. Die volle Funktionalität des Datensystems wird nur beim Query-Server benötigt, da die beiden anderen Server-Typen in ihrer Reinform keinen mengenorientierten DB-Zugriff gestatten.
In Abb. 1.9 sind zweistufige Client/Server-Architekturen (2-tier architectures) illustriert, die sowohl server- als auch client-seitige DBS-Funktionalität bereitstellen. Künftige Systeme können zudem mehrstufige Client/Server-Architekturen (n-tier architectures) umfassen [ORFA96], in denen die DBS-Funktionalität auf mehrere Ausführungsorte verteilt ist und dynamisch der Anwendungsabwicklung zugeordnet werden kann. Neben der Kernfunktionalität, die unser Schichtenmodell beschreibt, sind zur Realisierung aller DB-basierten Client/Server-Architekturen spezielle Zusatzfunktionen und -protokolle erforderlich, die den Rahmen unserer Betrachtungen allerdings sprengen [DEWI90, FRAN97, HÄRD95].
- die Aktualität des Konzeptionellen Schemas,
- die konsistente Modifikation verteilter Schemainformation usw.
betreffen [GRAY86, HÄRD90a].
Verteilte DBS bestehen aus autonomen Teilsystemen, die koordiniert zusammenarbeiten, um eine logisch integrierte DB bei physischer Verteilung von möglicherweise redundanten oder replizierten Daten zu verwalten. Im Hinblick auf Autonomie und Funktionszuordnung sind alle Teilsysteme (Knoten) Partnersysteme (peer system). Sie sind mit allen DBS-Funktionen ausgestattet und sind einander völlig gleichgestellt, d. h., jeder Knoten verfügt über alle Funktionen eines zentralisierten DBS und kann somit durch unser Schichtenmodell beschrieben werden (siehe Abb. 1.10). Eine Partitionierung von DBS-Funktionen dagegen resultiert in Client/Server-DBS, wie sie in Abschnitt 1.4.2 gestreift wurden. Als Prinzip der Datenzuordnung können Partitionierung (DB-Pi in Abb. 1.10), teilweise oder vollständige Replikation oder DB-Sharing [RAHM94] herangezogen werden, wobei zu berücksichtigen ist, daß DB-Sharing eine lokale Rechneranordnung erfordert, da jeder Rechner alle Externspeicher der DB direkt erreichen muß.[10] Abhängig von der gewählten Datenallokation ergeben sich verschiedene Verteilgranulate, mit denen sich die Transaktionslast den Knoten des verteilten DBS zur Verarbeitung zuteilen läßt.
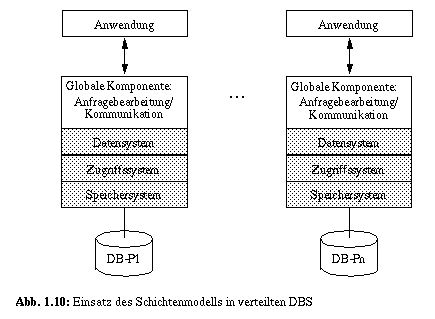
Das zentrale Problem, das ein verteiltes DBS zu lösen hat, ist die Bereitstellung von lokalen Benutzersichten trotz einer beliebigen physischen Verteilung und ggf. Replikation der Daten, so daß jedes Anwendungsprogramm den Eindruck hat, die Daten würden an einer Stelle, in einem DBS und auf dem Rechner gehalten, wo das jeweilige Anwendungsprogramm abläuft. Da jeder Knoten wie ein zentralisiertes DBS zwar volle Funktionalität, aber nur eine lokale Systemsicht auf "seine" Daten besitzt, ist die Gesamtarchitektur nach Abb. 1.10 um eine Komponente zu erweitern, mit der die globale Systemsicht hergestellt werden kann. Ein separates, zentralisiertes Teilsystem dafür einzurichten, würde einen "single point of failure" implizieren und außerdem einen Flaschenhals für die Systemleistung darstellen, was beides höchst unerwünschte Konsequenzen wären. Deshalb wird jeder Knoten um die erforderliche Funktionalität erweitert, wobei diese zusammen mit dem globalen Schema, der Verteilinformation sowie den systemweiten Koordinations- und Kommunikationsaufgaben vorteilhafterweise oberhalb der mengenorientierten DB-Schnittstelle anzusiedeln ist. Wegen der abstrakten Objektsicht und der Mengenorientierung dieser Schnittstelle lassen sich mit minimalem Kommunikationsaufwand Teilanfragen an Knoten verschicken und Ergebnismengen einsammeln. Die globale Komponente ist deshalb in Abb. 1.10 als eigenständige Schicht oberhalb des Datensystems illustriert.
Das Grundproblem verteilter Systeme, und insbesondere verteilter DBS, deren Teilsysteme gemeinsam einen globalen konsistenten DB-Zustand verwalten sollen, ist der Mangel an globalem (zentralisiertem) Wissen. Dieses Kernproblem läßt sich durch die "Coordinated Attack"-Aufgabe (Generals-Paradoxon) illustrieren, wo zwei (oder n) Generäle gemeinsam einen Angriff bei unsicherer Kommunikation koordinieren müssen. Symmetrische Protokolle zur Abstimmung hinterlassen immer einen Rest an Entscheidungsunsicherheit, der auch durch beliebig häufige Wiederholung solcher Abstimmungsrunden nicht beseitigt werden kann. Durch fallweise Zuordnung der Kontrolle und Koordination (Entscheidungsbefugnis) läßt sich dieses Kernproblem jedoch relativ leicht beheben. Da jeder Knoten volle Funktionalität besitzt, kann er auch fallweise die Koordination der verteilten Verarbeitung übernehmen. Das wichtigste Einsatzbeispiel hierfür ist das verteilte Zwei-Phasen-Commit-Protokoll, mit dessen Hilfe sich verteilte Transaktionen atomar abschließen lassen (siehe Abschnitt 15.8).
Verteilte DBS sind hardware-seitig durch mehrere unabhängige Rechner realisiert, sind also Mehrrechner-DBS. Als Architekturklassen unterscheidet man Shared-Disk- und Shared-Nothing-Architekturen[11] [BHID88, RAHM94]. Während das Shared-Disk-Prinzip die Erreichbarkeit aller Magnetplatten und damit lokale Verteilung (z. B. in einem Raum) impliziert, erlaubt der Shared-Nothing Ortsverteilung mit Partitionierung und Replikation der Daten. Parallele DBS sind Mehrrechner- oder Mehrprozessor-DBS. Deshalb können alle Shared-Nothing- und Shared-Disk-, aber auch Shared-Everything-Ansätze zur Realisierung paralleler DBS eingesetzt werden. Bei Shared-Everything-Architekturen sind ein gemeinsamer Hauptspeicher und gemeinsam genutzte Externspeicher vorhanden. Sie lassen sich als eng gekoppelte Mehrprozessor-Systeme realisieren, bei denen das Betriebssystem die Abstraktion eines Rechners bietet. Deshalb können zentralisierte DBS ablaufen, wobei mehrere Prozessoren zugleich DB-Operationen abwickeln können und damit die Realisierung von "echter" Parallelität ermöglichen. Was unser Schichtenmodell und seine Rolle bei der Modellbildung paralleler DBS anbelangt, so läßt sich wiederum der Aufbau jedes beteiligten Knotens damit beschreiben. Im Vergleich zu verteilten DBS, wo in der Regel eine Benutzertransaktion synchron (sequentiell) und verteilt (an den Knoten der benötigten DB-Partitionen) ausgeführt wird, versuchen parallele DBS typischerweise die gleiche Operation oder Funktion auf partitionierten Daten zu parallelisieren, um so die Antwortzeit für eine Anfrage oder Transaktion zu minimieren. Wegen dieser Antwortzeitminimierung kommen in der Regel nur lokale Rechneranordnungen mit breitbandigem Kommunikationsnetz bei der Realisierung von parallelen DBS zum Einsatz.
Es können hier weder die Eigenschaften von Mehrrechner-DBS vertieft noch spezielle Probleme, die sich bei ihrer Realisierung ergeben, berücksichtigt werden. Das betrifft vor allem Architekturen zur Unterstützung von Hochleistungssystemen. Überblicksartige oder die besonderen Eigenschaften dieser Architekturen herausstellende Darstellungen finden sich in [GRAY93, HÄRD86a, RAHM89, RAHM94, RAMA98, STON86a, STON96b, WILL82].
Beim betrieblichen Einsatz wickeln eine Vielzahl von Benutzern (oft >104) gleichzeitig Transaktionen ab, wobei natürlich auch Denkzeiten anfallen. Ihre PCs oder Terminals sind über unterschiedliche Leitungen, Netze und Kommunikationsprotokolle mit dem Transaktionssystem verknüpft; das Internet erlaubt sogar weltweit einfache und plattformunabhängige Zugriffsmöglichkeiten. Oft rufen viele Benutzer gleichzeitig dieselbe Funktion (mit jeweils eigenen aktuellen Parametern) auf, so daß im Prinzip ein TAP "hochgradig parallel" benutzt werden kann [GRAY93]. Solche Anwendungen veranlaßten die Entwicklung von Transaktionssystemen (früher auch DB/DC-Systeme genannt). Während die DB-Komponente für alle Aspekte der Datenhaltung und insbesondere für Datenunabhängigkeit zuständig ist, sorgt der TP-Monitor (DC-Komponente) für die Nachrichten- und TAP-Verwaltung und gewährleistet dabei Kommunikationsunabhängigkeit und isolierte Mehrfachbenutzbarkeit der TAPs [MEYE88].
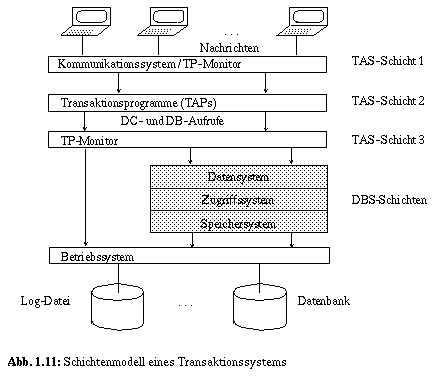
Die oberste Systemschicht (TAS-Schicht 1) ist für alle Aufgaben der Ein-/Ausgabe von/zu den Benutzern verantwortlich, wobei eine Reihe von Betriebssystemdiensten genutzt werden. Der Begriff Kommunikationssystem deutet darauf hin, daß hier alle Aufgaben der externen Kommunikation abgewickelt werden. Als Komponente des TP-Monitors organisiert es neben der Datenübertragung die Warteschlangen für die Eingabe- und Ergebnisnachrichten. Eingabenachrichten werden vom TP-Monitor aufbereitet, analysiert und der eigentlichen Verarbeitung zugeführt. Über den TAC wird erkannt, welche Funktion auszuführen ist. Dazu ist , falls erforderlich, für das entsprechende TAP eine Laufzeitumgebung (laden, initialisieren, Speicherplatz zuordnen) zu schaffen, bevor es die Ablaufkontrolle erhält.
TAS-Schicht 2 wird von der Menge der zur Anwendung gehörenden TAPs und den entsprechenden Verwaltungsfunktionen gebildet. In der Aufrufhierarchie der Transaktionsverarbeitung übernimmt das ausgewählte TAP die Eingabenachricht und beginnt nach Routineprüfungen die eigentliche Verarbeitung, die durch eine Reihe von Datei- oder DB-Zugriffen unterstützt wird. Mit Beendigung der Verarbeitung erzeugt das TAP eine Ausgabenachricht, die über den TP-Monitor an den Benutzer weitergeleitet wird.
Der TP-Monitor in TAS-Schicht 3 ist vor allem verantwortlich für die Abwicklung des Mehrbenutzerbetriebs (z. B. Multi-Tasking) und der Verwaltung der TAP-Aktivierungen, was auch eine Beteiligung an der Transaktionskoordination verlangt. Weiterhin registriert der TP-Monitor alle Aufrufe an die Datenhaltung, damit auch Transaktionsbeginn und -ende, und reicht sie entweder an das Dateisystem oder an das DBS weiter. Diese Aufrufregistrierung ist vor allem aus Gründen der Fehlerbehandlung wichtig, da der TP-Monitor bei Ausfall eines TAP die Transaktion DB-seitig zu schließen und den Benutzer zu benachrichtigen hat.
In [MEYE87] werden verschiedene Systemlösungen für verteilte Transaktionssysteme diskutiert, wobei gezeigt wird, daß grundsätzlich jede Modellschicht zur Bildung der globalen Systemsicht herangezogen werden kann. Wie in Abschnitt 1.4.3 erläutert, kann für das Herstellen der globalen Systemsicht ein verteiltes DBS herangezogen werden. In diesem Fall sind die Verteilungs-/Kommunikationsaufgaben im Datensystem anzusiedeln (Minimierung der Kommunikation, mengenorientierte Anforderungen). Die Funktionalität des verteilten DBS bestimmt die Art und Flexibilität der verteilten Datenhaltung, d. h., in der Regel sind nur homogene DB-Lösungen möglich. Unabhängig von der verteilten Datenhaltung kann jedoch eine Verteilung der Anwendungslogik auf ein oder mehrere (verteilte) TAPs erfolgen.
Die weiteren Lösungsvorschläge zielen darauf ab, die globale Systemsicht durch TP-Monitor-Funktionalität herzustellen. In allen Ansätzen ist es deshalb nicht erforderlich, Annahmen über die Datenhaltung zu treffen. Insbesondere ist in den folgenden drei Fällen die Einbindung heterogener Datenquellen oder verschiedenartiger DBS prinzipiell möglich.
* Soll auf der Ebene der TAPs, also in TAS-Schicht 2, die globale Systemsicht hergestellt werden, so ist es sehr wichtig, daß die TAPs von den Verteilungsaspekten der Daten und den Charakteristika der (verschiedenen) DBS isoliert werden. Zugriffe auf lokale und entfernte Daten müssen in einheitlicher Weise ausgeführt werden. Restrukturierung und Umverteilung der Daten schlägt sonst bis auf den Programmtext des TAP durch. Deshalb wurde hierfür das Prinzip der "Programmierten Verteilung" entwickelt, wobei DB-Operationen in Funktionen (stored procedures) gekapselt werden, die, vorab geplant und realisiert, von den beteiligten DB-Servern den TAPs zur Ausführung angeboten werden. Aufrufe solcher Funktionen und Ergebnisübermittlung erfolgen durch den TP-Monitor, was Ortsunabhängigkeit gewährleistet.
* Der entsprechende Lösungsansatz in TAS-Schicht 3 heißt "Aufrufweiterleitung" (function request shipping). Der TP-Monitor muß dafür in die Lage versetzt werden, die globale Systemsicht zu bilden. Er bestimmt den Knoten, der eine Datenanforderung bearbeiten kann, leitet den Auftrag weiter und empfängt das Ergebnis, das er dann dem TAP zur Verfügung stellt.
Bei den Ansätzen Aufrufweiterleitung und Programmierte Verteilung ist die Entwicklung knotenübergreifender Anwendungen möglich. Um Transaktionsschutz bieten zu können, müssen jedoch der TP-Monitor und alle teilnehmenden DBS kooperieren und gemeinsam verteilte Zwei-Phasen-Commit-Protokolle (2PC-Protokoll) abwickeln. Weitere Anwendungscharakteristika sowie Vor- und Nachteile der verschiedenen Lösungsansätze werden in [HÄRD90b] im Detail diskutiert und evaluiert.
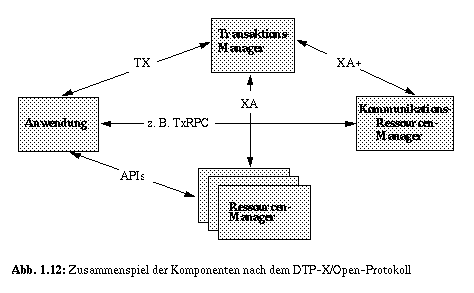 In Abb. 1.12 ist das Zusammenspiel der Komponenten mit den zugehörigen Schnittstellen gezeigt. Die Anwendung besitzt eine standardisierte Schnittstelle (TX) zum Transaktions-Manager, um Anwendungen mit Transaktionsschutz zu versorgen (Begin_TA, Commit_TA, Rollback_TA). Alle an einer Transaktion teilnehmenden Ressourcen-Manager benutzen mit dem Transaktions-Manager eine standardisierte Schnittstelle (XA), um Aufrufe mehrerer verschiedener Ressourcen-Manager in die (verteilte) Anwendungstransaktion einbinden zu können. Die wichtigsten Aufrufe der XA-Schnittstelle sind Join_TA, Prepare_TA, Commit_TA und Rollback_TA. Die entsprechenden Anwendungsprogrammierschnittstellen (APIs) zu den Ressourcen-Managern, z. B. SQL für relationale DBS, sind nicht im Rahmen von DTP-X/Open standardisiert.
In Abb. 1.12 ist das Zusammenspiel der Komponenten mit den zugehörigen Schnittstellen gezeigt. Die Anwendung besitzt eine standardisierte Schnittstelle (TX) zum Transaktions-Manager, um Anwendungen mit Transaktionsschutz zu versorgen (Begin_TA, Commit_TA, Rollback_TA). Alle an einer Transaktion teilnehmenden Ressourcen-Manager benutzen mit dem Transaktions-Manager eine standardisierte Schnittstelle (XA), um Aufrufe mehrerer verschiedener Ressourcen-Manager in die (verteilte) Anwendungstransaktion einbinden zu können. Die wichtigsten Aufrufe der XA-Schnittstelle sind Join_TA, Prepare_TA, Commit_TA und Rollback_TA. Die entsprechenden Anwendungsprogrammierschnittstellen (APIs) zu den Ressourcen-Managern, z. B. SQL für relationale DBS, sind nicht im Rahmen von DTP-X/Open standardisiert.
Man kann sich den Ablauf einer Anwendungstransaktion folgendermaßen vorstellen. Nach Anmeldung (Begin_TA) erhält die Anwendung für die begonnene Transaktion eine systemweit eindeutige Transaktions-ID (TRID) durch den Transaktions-Manager zugeteilt. Sie dient der Kontrolle der verteilten Transaktionsverarbeitung und wird jeder Anforderung der Anwendung an einen Ressourcen-Manager mitgegeben. Erhält ein Ressourcen-Manager von einer Transaktion erstmalig eine Dienstanforderung, so meldet er die TRID mit einem Join_TA-Aufruf dem (lokalen) Transaktions-Manager. Ab diesem Zeitpunkt ist der betreffende Ressourcen-Manager in die globale Transaktionskontrolle eingebunden und kann mit Rollback_TA u. a. in die Fehlerbehandlung oder mit Prepare_TA und Commit_TA in das 2PC-Protokoll einbezogen werden.
Für den verteilten Fall werden die Dienste von Kommunikations-Ressourcen-Manager herangezogen, die mit dem Transaktions-Manager eine erweitere Schnittstelle (XA+) zur Transaktionskontrolle und eine Reihe von standardisierten Schnittstellen zur Anwendung besitzen (TxRPC, CPI-C V2, XATMI, [ORFA96]).[12] Das Zusammenspiel der Komponenten ist in jedem Knoten entsprechend Abb. 1.12 organisiert. Bei knotenübergreifender Transaktionsverarbeitung übernehmen die Kommunikations-Ressourcen-Manager der beteiligten Knoten die Abwicklung der Kommunikation. Um verteilten Transaktionsschutz zu gewährleisten, melden sie die erstmalige knotenübergreifende Dienstanforderung einer Transaktion beim jeweiligen lokalen Transaktions-Manager ab/an, so daß auch knotenübergreifend Fehlerbehandlung oder Commit-Verarbeitung ermöglicht wird.
Die beteiligten Ressourcen-Manager sind Systemkomponenten, die in Kooperation Transaktionsschutz für ihre gemeinsam nutzbaren Betriebsmittel übernehmen, d. h., sie gestatten die externe Koordination der Aktualisierung ihrer Betriebsmittel durch 2PC-Protokolle. Der TP-Monitor "orchestriert" und integriert solche verschiedenartigen Systemkomponenten, um eine gleichförmige Schnittstelle für Anwendungen und Operationen mit demselben Verhalten im Fehlerfall (failure semantics) zu bieten. Solche komponentenorientierten Architekturen versprechen einen hohen Grad und Flexibilität, Skalierbarkeit und Offenheit für die Integration neuer Ressourcen-Manager. Sie berücksichtigen zugleich alle Aspekte der Transaktionsverwaltung, der verteilten Verarbeitung sowie der Anpaßbarkeit des Systems an verschiedene Lastcharakteristika [REUT90].
Der Beschreibungsrahmen unseres Schichtenmodells und die einzuführenden Implementierungskonzepte und -techniken sind für alle Ressourcen-Manager geeignet, die Daten verschiedensten Typs verwalten. Das betrifft DBS, Dateisysteme, Archivierungssysteme für Daten oder große Objekte, Systeme zur Verwaltung persistenter Warteschlangen u. a., wenn auch nicht immer alle Schichten und die gesamte Funktionalität benötigt werden. Die Realisierung anderer Arten von Ressourcen-Managern, beispielsweise für die Verwaltung von Ausgabefenstern (Windows) oder persistenten Programmiersprachenobjekten, verlangt dagegen neue Konzepte und Techniken, die im Rahmen komponentenorientierter Systemarchitekturen bereitgestellt werden oder noch zu entwickeln sind.
[9] Durch diese starke Anwendungsverflechtung wird die Mehrsprachenfähigkeit von OODBS eingeschränkt. Sie bedingt zugleich einen geringeren Grad an Anwendungsisolation, so daß beispielsweise Fehler in Anwendungsprogrammen zu unbemerkter Verfälschung von im Arbeitsbereich gepufferten DB-Daten führen können. Außerdem ist die client-seitige DBS-Verarbeitung, die eine Übertragung aller benötigten Daten (data shipping) und ein Zurückschreiben aller Änderungen impliziert, ein wesentlicher Grund für die mangelnde Skalierbarkeit von OODBS.
[10] Nur bei DB-Sharing (Shared-Disk-Architekturen) oder vollständiger Replikation kann eine Transaktion immer vollständig in einem Knoten abgewickelt werden. In den anderen Fällen "folgt die Last den Daten", d. h., es sind Funktionsaufrufe oder Teiltransaktionen zu verschicken.