





2.1 Datenbanksysteme

Das Relationenmodell schreibt zwei modellinhärente Integritätsbedingungen vor, die sogenannten Relationalen Invarianten. Die Primärschlüsselbedingung verlangt, daß zu jeder Relation ein Attribut bzw. eine Kombination von Attributen als Primärschlüssel fungiert, mit dem Tupel eindeutig identifiziert werden können. In Abb. 2-1 bilden z.B. die Attribute KTONR (Relation KONTO) und KNR (Relation KUNDE) geeignete Primärschlüssel. Die zweite modellinhärente Integritätsbedingung betrifft sogenannte Fremdschlüssel, mit denen Beziehungen zwischen Relationen realisiert werden können. In Abb. 2-1 ist das Attribut KNR (Kundennummer) in Relation KONTO ein solcher Fremdschlüssel, mit dem der Inhaber eines Kontos durch einen Verweis auf den Primärschlüssel der Relation KUNDE repräsentiert wird. Die Fremdschlüsselbedingung verlangt, daß das durch einen Fremdschlüsselwert referenzierte Tupel in der Datenbank existiert, d.h., daß in der referenzierten Relation ein entsprechender Primärschlüsselwert definiert sein muß (referentielle Integrität).
Zur Beschreibung relationaler Anfragen greifen wir (neben SQL) vor allem auf die Relationenalgebra zurück. Die Relationenalgebra erlaubt eine kompakte Darstellung von Operationen und spezifiziert explizit die Basisoperatoren, die bei der Anfragebearbeitung auszuführen sind. Die Operatoren der Relationenalgebra sind mengenorientiert, da sie aus einer oder zwei Eingaberelation(en) wiederum eine Relation erzeugen. Neben allgemeinen mengentheoretischen Operatoren wie Vereinigung (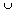 ), Durchschnittsbildung (
), Durchschnittsbildung (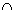 ), kartesisches Produkt (
), kartesisches Produkt (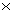 ) oder Differenz interessieren vor allem die relationalen Operatoren Selektion (Restriktion), Projektion und Verbund (Join). Mit der Selektion
) oder Differenz interessieren vor allem die relationalen Operatoren Selektion (Restriktion), Projektion und Verbund (Join). Mit der Selektion

wird eine zeilenweise (horizontale) Teilmenge einer Relation R gebildet, die alle Tupel enthält, die das Selektionsprädikat P erfüllen. Ein Beispiel dazu findet sich in Abb. 2-2a. Die Projektion

bildet eine spaltenweise (vertikale) Teilmenge der Eingaberelation, wobei alle nicht spezifizierten Attribute "weggefiltert" werden (Beispiel: Abb. 2-2b). Dabei werden zudem Duplikate eliminiert, um die Mengeneigenschaft der Ergebnisrelation zu wahren. Der Verbund (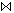 ) schließlich erlaubt die Verknüpfung zweier Relationen, die Attribute mit übereinstimmenden Domains besitzen. Der mit Abstand wichtigste Verbundtyp ist der Gleichverbund (Equi-Join), bei dem die Verknüpfung durch eine Gleichheitsbedingung auf den Verbundattributen definiert ist. Der Gleichverbund zwischen Relation R mit Verbundattribut r und Relation S mit Verbundattribut s kann als Selektion auf dem kartesischen Produkt zwischen R und S definiert werden:
) schließlich erlaubt die Verknüpfung zweier Relationen, die Attribute mit übereinstimmenden Domains besitzen. Der mit Abstand wichtigste Verbundtyp ist der Gleichverbund (Equi-Join), bei dem die Verknüpfung durch eine Gleichheitsbedingung auf den Verbundattributen definiert ist. Der Gleichverbund zwischen Relation R mit Verbundattribut r und Relation S mit Verbundattribut s kann als Selektion auf dem kartesischen Produkt zwischen R und S definiert werden:
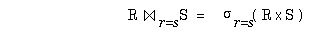
Der natürliche Verbund zwischen zwei Relationen, bei denen die Verbundattribute den gleichen Namen besitzen, ist definiert als Gleichverbund zwischen den Relationen, wobei die Verbundattribute nur einmal im Ergebnis vorkommen. Aufgrund der Namenskonvention kann beim natürlichen Verbund die Join-Bedingung weggelassen werden (R 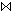 S). Abb. 2-2c zeigt ein Beispiel für den natürlichen Verbund.
S). Abb. 2-2c zeigt ein Beispiel für den natürlichen Verbund.
Der Semi-Join zwischen zwei Relationen R und S (R 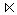 S) ist definiert als ein Verbund, in dessen Ergebnis nur Attribute der Relation R enthalten sind:
S) ist definiert als ein Verbund, in dessen Ergebnis nur Attribute der Relation R enthalten sind:
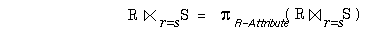
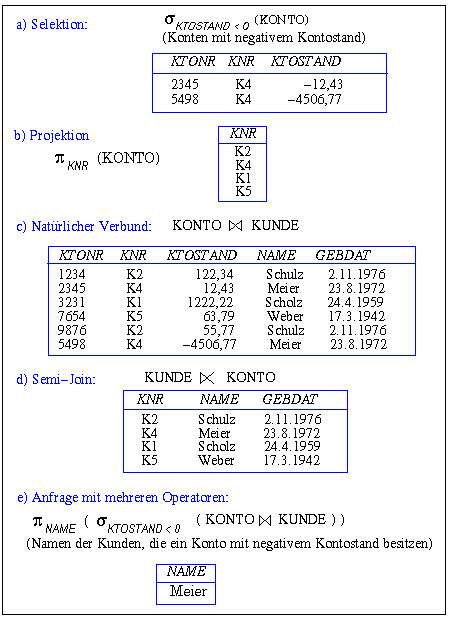
Da die Operatoren Relationen als Eingabe verwenden und wiederum Relationen erzeugen, können sie miteinander kombiniert werden, um komplexere Anfragen zu formulieren. Ein Beispiel dazu ist in Abb. 2-2e gezeigt.
In der Praxis werden DB-Anfragen natürlich in einer benutzerfreundlicheren und deskriptiveren Anfragesprache als der Relationenalgebra formuliert. Hier hat sich SQL eindeutig durchgesetzt. Diese Anfragesprache wird von nahezu allen Datenbanksystemen unterstützt und ist im Rahmen der ISO standardisiert. Der aktuelle Standard (SQL2, SQL92) ist gegenüber seinen Vorgängerversionen sehr mächtig und umfassend und wird von existierenden Implementierungen derzeit meist nur teilweise abgedeckt. Für dieses Buch werden lediglich geringe SQL-Kenntnisse vorausgesetzt, da nur vereinzelt Beispiele in SQL formuliert werden, die zudem weitgehend selbsterklärend sein dürften. Die Anfrage aus Abb. 2-2e würde in SQL z.B. folgendermaßen lauten:

Besonderheiten von SQL, die natürlich auch durch Mehrrechner-DBS zu unterstützen sind, betreffen u.a. die Berechnung sogenannter Aggregatfunktionen (MIN, MAX, SUM, COUNT, AVG) sowie die optionale Sortierung von Ergebnismengen. Für eine Einführung in SQL sei auf die reichlich vorhandene Literatur verwiesen; der aktuelle Sprachumfang von ISO-SQL wird z.B. in [DD92, MS92] beschrieben.