





11 Verteilte Transaktionssysteme
11.1 Transaktionsverarbeitung in Client/Server-Systemen
Traditionellerweise erfolgte die Transaktionsverarbeitung (Online Transaction Processing, OLTP) zentralisiert auf allgemeinen Großrechnern, auf die über einfache Terminals zugegriffen wurde. Die Datenbank- und Anwendungsverarbeitung erfolgte - unter Kontrolle von DBS und TP-Monitor - vollständig auf dem Mainframe, ebenso Präsentationsdienste zur Ein-/Ausgabe mit dem Benutzer (Maskenverwaltung, Formatkonversionen, etc.).
Solche zentralisierten Transaktionssysteme (Kap. 2.1.4) werden jedoch zunehmend durch Client/Server-Transaktionssysteme abgelöst. Dabei erfolgt eine Zerlegung der Funktionen in Client- und Server-Komponenten, die unterschiedlichen Rechnern zugeordnet werden können. Als Client-Rechner fungieren dabei meist leistungsfähige PCs und Workstations, die fast an jedem Arbeitsplatz verfügbar sind und die einfachen Terminals weitgehend abgelöst haben. Damit lassen sich eine Reihe wesentlicher Vorteile erreichen:
- Durch die Ausführung von Teilen der Transaktionsverarbeitung auf Client-Rechnern können die zentralen Server-Rechner erheblich entlastet werden, so daß insgesamt ein besseres Leistungsverhalten möglich wird (höherer Server-Durchsatz).
- Die Nutzung von PCs und Workstations läßt eine signifikante Verbesserung der Kosteneffektivität gegenüber dem zentralisierten Mainframe-Ansatz erwarten. Dieser Effekt kann noch verbessert werden, indem auch in den Server-Rechnern leistungsfähige Mikroprozessoren eingesetzt werden (z.B. Multiprozessoren oder Parallelrechner auf Mikroprozessorbasis).
- Die Grafikfähigkeiten von Workstations und PCs (Fenstertechniken, etc.) erlauben eine starke Verbesserung der Benutzeroberflächen.
- Es ist relativ einfach, mehrere dedizierte Server für unterschiedliche Aufgaben in die Verarbeitung einzubeziehen. Damit wird auch der Zugriff auf mehrere unabhängige DB-Server (heterogene Datenbanken) möglich.
Für die Aufteilung der zur Transaktionsverarbeitung benötigten Funktionen der Präsentation, Anwendungsprogramme (Transaktionsprogramme) und DB-Verarbeitung bestehen im wesentlichen vier Alternativen, die in Abb. 11-2 dargestellt sind. Jede dieser Verteilungsformen geht einher mit einem unterschiedlichen Aufrufgranulat zwischen Client- und Server-System:
Abb. 11-2: Aufgabenteilung in Client/Server-Transaktionssystemen
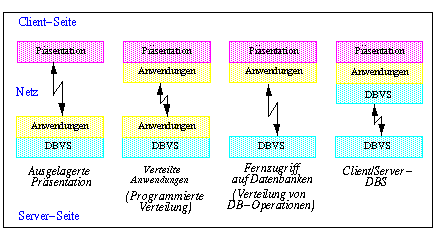
- Der erste Ansatz der ausgelagerten Präsentation beläßt Anwendungen und DB-Verarbeitung vollständig auf Server-Seite und führt lediglich die Präsentationsaufgaben (Realisierung der graphischen Benutzeroberfläche) im Client-System durch. Dies stellt die minimale Funktionalität dar, die client-seitig ausgeführt werden sollte; sie kann jedoch bereits eine spürbare Entlastung der Server bewirken. Das Aufrufgranulat zum Server sind wie in zentralisierten Transaktionssysteme ganze Transaktionsaufträge.
- Beim Ansatz der verteilten Anwendungen werden Anwendungen zum Teil auf den Client-Rechnern ausgeführt, so daß diese weitergehend als bei der ausgelagerten Präsentation genutzt werden können. Allerdings können die Client-Anwendungen nicht unmittelbar mit den Server-DBVS kommunizieren, sondern müssen Anwendungsprogramme auf den Servern starten, um die dort erreichbaren Daten zu referenzieren. Aufrufeinheit ist somit eine Anwendungsfunktion bzw. Transaktionsprogramm, so daß man auch von programmierter Verteilung spricht [HM90]. Der Aufruf erfolgt häufig über RPCs (remote procedure calls). Ein Vorteil des Ansatzes liegt darin, daß es einfach möglich ist, Anwendungsfunktionen verschiedener Rechner aufzurufen und somit auf mehrere Datenbanken zuzugreifen.
- Ein Fernzugriff auf Datenbanken (Verteilung von DB-Operationen) liegt vor, wenn Client-Anwendungen direkt DB-Operationen an Server-DBS stellen. In diesem Fall werden die Anwendungsfunktionen vollständig auf Client-Seite abgewickelt. Das Aufrufgranulat sind einzelne DB-Operationen (z.B. SQL-Anweisungen). Diese Verteilungsform ist für den Zugriff auf einen Server einfach realisierbar und wird von fast allen DBS unterstützt. Die Zusammenarbeit mit mehreren unabhängigen DB-Servern ist problematischer, findet jedoch auch zunehmend Verbreitung (s.u.).
- Den aufwendigsten Ansatz stellen Client/Server-DBS dar, bei denen auch auf Client-Seite eine DB-Verarbeitung erfolgt und das Client-DBVS mit den Server-DBVS kooperiert. Damit liegt nach unserer Terminologie hier bereits ein Mehrrechner-DBS-Ansatz und kein verteiltes Transaktionssystem mehr vor. Ein solcher Ansatz wird v.a. in objekt-orientierten DBS verfolgt, wobei ein DBS funktional auf Client- und Server-Rechner (Workstation/Server-DBS) aufgeteilt wird (Kap. 3.3.1). Es handelt sich damit um integrierte Mehrrechner-DBS. Auch für föderative DBS kann ein Client/Server-DBS-Ansatz relevant sein, wenn DB-Operationen von einem Client-DBS aus zur verteilten Verarbeitung unter mehreren unabhängigen Server-DBS aufgeteilt werden. In beiden Fällen stellen Teile von DB-Operationen (bzw. Satz- oder Seitenanforderungen) die Aufrufgranulate dar.
Da der erste Ansatz ganze Transaktionsaufträge als Verteileinheiten benutzt und der letzte zu den Mehrrechner-DBS zählt, bestehen im wesentlichen die Alternativen der programmierten Verteilung und der Verteilung von DB-Operationen zur verteilten Transaktionsausführung. Beide Ansätze gestatten den Zugriff auf mehrere heterogene Datenbanken in einer Transaktion und werden im nächsten Abschnitt näher untersucht.
Zuvor sei jedoch noch auf einige Probleme von Client/Server-Transaktionssystemen hingewiesen. Zunächst ergeben sich natürlich Schwierigkeiten durch die Notwendigkeit der Interoperabilität mit mehreren heterogenen DBVS und der Integration bestehender Anwendungen und Datenbanken. Darauf wird im folgenden noch näher eingegangen. Einen Nachteil gegenüber zentralisierten Transaktionssystemen stellt die weitaus komplexere Administration dar. So sind meist sehr viele Client-Rechner zu verwalten, die jeweils eigene System- und Anwendungs-Software ausführen, die auf einem aktuellen und miteinander verträglichen Stand zu halten sind. Die Client-Rechner selbst sind als inhärent unzuverlässig einzustufen, da sie z.B. vom jeweiligen Benutzer abgeschaltet werden können u.ä. Daher sollten kritische Daten (Log-Daten, nicht-private Datenbanken) und Funktionen (Commit-Koordinierung) nur auf zuverlässigen Server-Rechnern vorgehalten werden. Entscheidend für die Zuverlässigkeit des gesamten Systems ist die Unterstützung der transaktionsbasierten Verarbeitung, da sie eine weitgehende Fehlerisolation Anwendungen gegenüber ermöglicht und die Konsistenz der Daten auch im Fehlerfall gewahrt bleibt.