





17 Datenverteilung in Parallelen DBS
17.2 Fragmentierung
Alle parallelen Shared-Nothing-DBS basieren auf einer horizontalen Fragmentierung von Relationen, da diese eine disjunkte Zerlegung der Daten definiert, die unmittelbar für Datenparallelität genutzt werden kann (Kap. 5.3.3). Ferner läßt sich dabei im Gegensatz zur vertikalen Fragmentierung auch leicht eine sehr große Anzahl von Fragmenten und somit eine weitgehende Parallelisierung erreichen. Im wesentlichen finden drei Fragmentierungsansätze Anwendung für parallele Shared-Nothing-Systeme: Round-Robin, Hash-Fragmentierung sowie Bereichsfragmentierung (Abb. 17-3), die nachfolgend näher diskutiert werden. Wir nehmen dabei an, daß M Fragmente zu bestimmen seien, wobei im allgemeinen M=D gilt[76]. Die Zuordnung der Fragmente zu Rechnern ist Aufgabe der Allokation (s.u.).
Bei der Round-Robin-artigen Fragmentierung werden die Sätze einer Relation reihum den M Fragmenten zugewiesen, so daß der i-te Satz der Relation dem Fragment (i MOD M) + 1 zugeordnet wird. Damit wird eine Aufteilung der Relation in M gleich große Fragmente erreicht. Dies führt zu einer günstigen Lastbalancierung, falls die einzelnen Sätze der Relation mit gleicher Wahrscheinlichkeit referenziert werden. Da für die Datenverteilung keine Attributwerte berücksichtigt werden, ist jedoch i.a. für jede Anfrage auf der Relation eine Bearbeitung aller M Fragmente erforderlich.
Abb. 17-3: Alternativen zur horizontalen Fragmentierung [DG92]

Die Ansätze der Hash- und Bereichsfragmentierung versuchen diesen Nachteil abzuschwächen, indem sie die Datenverteilung über die Werte eines Attributs (bzw. einer Menge von Attributen) definieren. Dieses Fragmentierungs- bzw. Verteilattribut ist beliebig wählbar, jedoch wird meist der Primärschlüssel verwendet. Bei der Hash-Fragmentierung wird die Zerlegung der Relation durch eine Hash-Funktion auf dem Verteilattribut festgelegt, die jeden Satz auf eines der M Fragmente abbildet. Die Verteilung der Attributwerte sowie die Güte der Hash-Funktion bestimmen, ob eine ähnlich gleichmäßige Datenverteilung wie bei Round-Robin erreicht werden kann. Von Vorteil ist, daß die Bearbeitung von exakten (exact match) Anfragen bezüglich des Verteilattributes, welche nur Sätze zu einem festgelegten Attributwert als Ergebnis liefern, durch Anwendung der Hash-Funktion auf einen Rechner beschränkt werden kann (minimaler Kommunikationsaufwand). Auch für Join-Berechnungen, bei denen das Join-Attribut mit dem Verteilattribut übereinstimmt, ergeben sich signifikante Einsparmöglichkeiten (s. Kap. 18.3.2).
Die Bereichsfragmentierung verwendet disjunkte und vollständige Wertebereichsunterteilungen auf dem Verteilattribut anstelle einer Hash-Funktion. Damit lassen sich wie für eine Hash-Fragmentierung Exact-Match-Anfragen bezüglich des Verteilattributes auf ein Fragment (1 Rechner, 1 Platte) beschränken. Daneben können aber auch Bereichsanfragen (range queries) bezüglich des Verteilattributs auf die relevante Teilmenge der Fragmente beschränkt werden, so daß für sie ein geringerer Kommunikationsaufwand als bei Hash-Fragmentierung möglich wird. Ein weiterer Vorteil liegt darin, daß i.a. auch bei ungleichmäßiger Werteverteilung eine Zerlegung in etwa gleich große Fragmente erreichbar ist [DNSS92]. Andererseits erfordert die Bereichsfragmentierung genaue Kenntnisse über die Werteverteilungen und ist daher i.a. schwieriger festzulegen als eine Hash-Fragmentierung.
Beispiel 17-2
- Die KONTO-Relation einer Bankanwendung soll über den Primärschlüssel KTONR in 25 Fragmente zerlegt werden. Im Falle einer Hash-Fragmentierung könnte dies z.B. durch die Hash-Funktion h (KTONR) = 1 + (KTONR MOD 25) erfolgen. Eine Bereichsfragmentierung muß dagegen auf die vergebenen Werte für KTONR abgestimmt werden, um sicherzustellen, daß jede Kontonummer berücksichtigt wird und die einzelnen Fragmente möglichst gleichviele Sätze umfassen. Exact-Match-Anfragen (z.B. KTONR = 4711) können in beiden Fällen auf ein Fragment beschränkt werden. Bereichsanfragen über die Kontonummer (z.B. KTONR < 200.000) lassen sich lediglich bei der Bereichsfragmentierung auf eine Teilmenge der Fragmente eingrenzen, was vor allem für selektive Anfragen vorteilhaft ist. Für die Hash-Fragmentierung wird in diesem Fall der Zugriff auf alle 25 Fragmente erforderlich. Kontenzugriffe über den Namen des Kontoinhabers (anstatt über die Kontonummer) müssten in beiden Fällen auf allen Fragmenten bearbeitet werden.
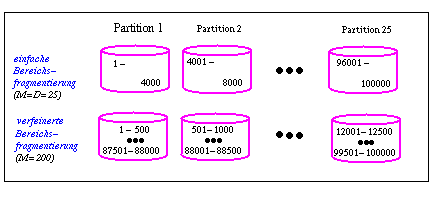
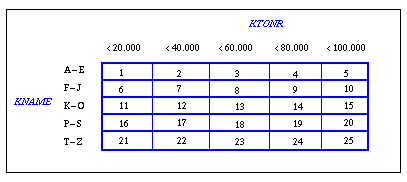
Im Falle der Bereichsfragmentierung kann die Beschränkung auf M=D Fragmente eine ungünstige Parallelisierung und Lastbalancierung für Bereichsanfragen verursachen. Denn damit werden Bereichsanfragen auf dem Fragmentierungsattribut auf die minimale Anzahl von Prozessoren s*D beschränkt, wobei s der mittlere Anteil sich qualifizierender Tupel sei (0 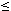 s
s 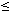 1). Wenn für diese Bereichsanfragen jedoch popt > s*D gilt, wird zwar ein geringer Kommunikationsaufwand, aber aufgrund einer zu geringen Parallelisierung u.U. eine schlechtere Antwortzeit als bei Verarbeitung auf D Knoten wie bei der Hash-Fragmentierung erreicht. Eine in [GD90] beschriebene Abhilfemöglichkeit besteht darin, eine Verfeinerung der Fragmentierung vorzunehmen, so daß die mittlere Ergebnismenge von s*K Tupeln (K = Kardinalität der Relation) auf popt Fragmente verteilt wird. Dies kann durch eine Fragmentierung erreicht werden, bei der im Mittel etwa s*K / popt Tupel pro Fragment entfallen, so daß insgesamt M = popt / s Fragmente zu bestimmen sind. Werden "aufeinanderfolgende" Fragmentbereiche jeweils verschiedenen Prozessoren zugeordnet, kann so für Bereichsanfragen auf dem Fragmentierungsattribut die optimale Parallelität erreicht werden. Der Preis für diese Flexibilität gegenüber einer einfachen Bereichsfragmentierung (M=D) und einer Hash-Fragmentierung liegt vor allem in der aufwendigen Bestimmung der Fragmentierung sowie der aufgrund der potentiell sehr großen Anzahl von Fragmenten teureren Verwaltung der Verteilungsinformation.
1). Wenn für diese Bereichsanfragen jedoch popt > s*D gilt, wird zwar ein geringer Kommunikationsaufwand, aber aufgrund einer zu geringen Parallelisierung u.U. eine schlechtere Antwortzeit als bei Verarbeitung auf D Knoten wie bei der Hash-Fragmentierung erreicht. Eine in [GD90] beschriebene Abhilfemöglichkeit besteht darin, eine Verfeinerung der Fragmentierung vorzunehmen, so daß die mittlere Ergebnismenge von s*K Tupeln (K = Kardinalität der Relation) auf popt Fragmente verteilt wird. Dies kann durch eine Fragmentierung erreicht werden, bei der im Mittel etwa s*K / popt Tupel pro Fragment entfallen, so daß insgesamt M = popt / s Fragmente zu bestimmen sind. Werden "aufeinanderfolgende" Fragmentbereiche jeweils verschiedenen Prozessoren zugeordnet, kann so für Bereichsanfragen auf dem Fragmentierungsattribut die optimale Parallelität erreicht werden. Der Preis für diese Flexibilität gegenüber einer einfachen Bereichsfragmentierung (M=D) und einer Hash-Fragmentierung liegt vor allem in der aufwendigen Bestimmung der Fragmentierung sowie der aufgrund der potentiell sehr großen Anzahl von Fragmenten teureren Verwaltung der Verteilungsinformation.
Beispiel 17-3
- Für die KONTO-Relation aus dem vorherigen Beispiel sei K=100.000, und für Bereichsanfragen über KTONR seien s = 0.05 und popt=10. Ferner soll D=25 gelten. Bei der einfachen Bereichsfragmentierung (Abb. 17-4 oben) sowie der Hash-Fragmentierung werden somit 25 Fragmente mit jeweils etwa 4000 Konten bestimmt. Die einfache Bereichsfragmentierung begrenzt Bereichsanfragen auf KTONR, welche im Mittel 5000 Sätze betreffen, auf 2 Fragmente (Prozessoren), während bei der Hash-Fragmentierung alle 25 Prozessoren involviert werden. Bei der verfeinerten Fragmentierung (Abb. 17-4 unten) werden M= 10/0.05 = 200 Fragmente mit jeweils etwa 500 Tupeln gebildet. Diese werden dann wie gezeigt reihum den 25 Prozessoren zugeordnet, so daß jede Partition 8 Fragmente umfaßt. Bereichsanfragen auf KTONR werden somit im Mittel auf 10 bis 11 Prozessoren verteilt, so daß der optimale Parallelitätsgrad unterstützt wird.
Abb. 17-4: Einfache vs. verfeinerte Bereichsfragmentierung
Eine Einschränkung bei Hash- sowie Bereichsfragmentierung ist, daß nur Anfragen bezüglich des Verteilattributs auf eine Teilmenge der Fragmente (Rechner) eingeschränkt werden können, für alle anderen Anfragen dagegen alle Fragmente zu involvieren sind. Eine Verbesserungsmöglichkeit bietet eine mehrdimensionale Bereichsfragmentierung, bei der mehrere Attribute gleichberechtigt zur Definition der Fragmentierung verwendet werden [GDQ92]. Über ein relativ kompaktes (Grid-)Directory kann dabei für jedes der beteiligten Fragmentierungsattribute festgestellt werden, welche Fragmente relevante Tupel für eine Bereichs- oder Exact-Match-Anfrage enthalten. Damit lassen sich für Anfragen auf mehreren Attributen Kommunikationseinsparungen gegenüber einer Verarbeitung auf allen Fragmenten erzielen. Auf der anderen Seite ergibt sich bezogen auf ein Attribut ein Mehraufwand an Kommunikation gegenüber einer eindimensionalen Fragmentierung auf diesem Attribut. Daher ist eine mehrdimensionale Bereichsfragmentierung i.a. nur sinnvoll, wenn über mehrere Attribute in etwa gleich häufig zugegriffen wird.
Beispiel 17-4
- Abb. 17-5 zeigt eine zweidimensionale Bereichsfragmentierung der KONTO-Relation über die Attribute KTONR und KNAME (Kundenname). Diese erlaubt Exact-Match- und Bereichsanfragen bezüglich jedes der beiden Attribute auf 5 Rechner zu begrenzen, falls jedes der Fragmente einem eigenen Rechner zugeordnet ist. Eine einfache Bereichsfragmentierung könnte Anfragen für eines der Attribute auf 1 Rechner eingrenzen, würde jedoch für Anfragen bezüglich des anderen Attributes alle 25 Rechner involvieren. Wenn beide Attribute mit gleicher Häufigkeit referenziert werden, ergibt dies einen Durchschnitt von 13 Rechnern pro Anfrage gegenüber 5 für die zweidimensionale Bereichsfragmentierung. Erfolgen die Kontenzugriffe dagegen in 90% der Fälle über KTONR und nur in 10% über den Kundennamen, schneidet die eindimensionale Fragmentierung über KTONR besser ab (im Mittel 3,4 Knoten pro Anfrage gegenüber 5).
Abb. 17-5: Mehrdimensionale Bereichspartitionierung (Beispiel)
[76] Es kann jedoch auch eine weitergehende Fragmentierung vorgenommen werden (M > D), um größere Freiheitsgrade zur Bildung von Partitionen zu erhalten.