





17 Datenverteilung in Parallelen DBS
17.4 Replikation
Ähnlich wie in Verteilten DBS (Kap. 9) kann in lokal verteilten Shared-Nothing-Systemen die Fehlertoleranz gegenüber Rechnerausfällen durch replizierte Speicherung der Daten erhöht werden. Im lokalen Fall spielen jedoch die Robustheit gegenüber Netzwerk-Partitionierungen sowie die Unterstützung von geographischer Zugriffslokalität eine untergeordnete Rolle. Dafür soll jetzt die Replikation auch zur schnellen Behandlung von Plattenfehlern sowie zur Verbesserung der Lastbalancierung genutzt werden. Wir stellen dazu im folgenden drei Ansätze vor, die in Produkten bzw. Prototypen realisiert wurden: Spiegelplatten, verstreute Replikation sowie verkettete Replikation. Alle drei Ansätzen verwenden für replizierte Daten jeweils zwei Kopien, so daß sich der Speicherplatzbedarf verdoppelt[77]. Zur Aktualisierung der Replikate gehen wir von einer einfachen Write-All-Strategie aus, bei der beide Kopien jeweils parallel geändert werden.
Spiegelplatten
Der Einsatz von Spiegelplatten (mirrored disks, shadowed disks) ist bereits in zentralisierten DBS zur schnellen Behandlung von Plattenfehlern weitverbreitet. Dabei wird eine "logische" Platte physisch durch zwei Platten mit identischem Inhalt realisiert. Im Falle eines Plattenfehlers kann die Verarbeitung mit der überlebenden Kopie nahezu unterbrechungsfrei fortgesetzt werden[78]. Schreibzugriffe werden parallel auf beiden Kopien ausgeführt, so daß sich i.a. nur eine geringe Erhöhung der Schreibdauer verglichen mit einer einfachen Platte ergibt. Auf der anderen Seite können Lesezugriffe erheblich beschleunigt werden, da stets die Platte mit der geringsten Armpositionierungszeit verwendet werden kann [Bi89]. Alternativ dazu kann eine Lastbalancierung unterstützt werden, indem Lesezugriffe zur Reduzierung von Wartezeiten gleichmäßig auf beide Platten verteilt werden. Spiegelplatten erlauben somit eine Verdoppelung der E/A-Rate und Bandbreite für Lesezugriffe. Die Verwaltung der Spiegelplatten erfolgt i.a. transparent für das DBS durch Betriebssystem-Software (Dateisystem) oder durch die Platten-Controller.
Diese Eigenschaften von Spiegelplatten bleiben auch beim Einsatz innerhalb von Shared-Nothing-Systemen erhalten, wie er etwa in Tandem-Systemen seit langem praktiziert wird [Ka78]. Dabei ist jedes Plattenpaar mit zwei Rechnern verbunden, wobei jedoch zu jedem Zeitpunkt nur von einem Rechner aus auf ein Plattenpaar zugegriffen wird (fett markierte Verbindung in Abb. 17-6). Es liegt somit keine rechnerübergreifende Replikation der Daten vor, und Lese- und Schreiboperationen sowie die Behandlung von Plattenfehlern können wie im zentralen Fall abgewickelt werden. Nach Ausfall eines Rechners R1 wird dessen Partition P1 vollständig von dem Rechner R2 übernommen, der mit den Platten von R1 verbunden ist. Damit bleibt der Zugriff auf P1 weiterhin möglich (nachdem R2 die Crash-Recovery für R1 durchgeführt hat). Allerdings ist während der Ausfallzeit mit einer ungünstigen Lastbalancierung zu rechnen, da der übernehmende Rechner R2 nun die Zugriffe auf zwei Partitionen zu verarbeiten hat. Für diesen Rechner ist somit eine Überlastung sehr wahrscheinlich. Auf der anderen Seite wird eine sehr hohe Datenverfügbarkeit unterstützt, da der Zugriff auf Partition P1 erst dann unmöglich wird, wenn sowohl R1 als auch R2 ausfallen.
Abb. 17-6: Einsatz von Spiegelplatten bei Shared-Nothing (Tandem)
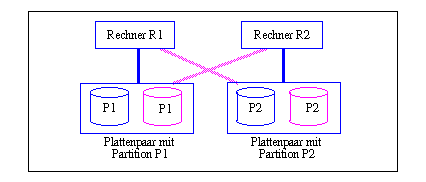
Die auf jeweils einen Rechner beschränkte Nutzung von Spiegelplatten bedeutet, daß diese Form der Replikation keine Vorteile für die Crash-Recovery mit sich bringt. Denn die Übernahme der Partition eines ausgefallenen Rechners durch einen überlebenden Rechner ist offenbar auch ohne Spiegelplatten anwendbar. Wäre dagegen die Kopie einer Partition bereits im Normalbetrieb einem anderen Knoten zugeordnet, würde die Aktualisierung der entfernten Kopie Kommunikation erfordern und damit teurer werden. Die Nutzung beider Kopien zur Lastbalancierung müßte zudem durch das DBS unterstützt werden und wäre wesentlich aufwendiger zu realisieren als die rechnerlokale Lastbalancierung für lesende Plattenzugriffe.
Verstreute Replikation
Zur Crash- und Platten-Recovery wird im Shared-Nothing-System von Teradata der Ansatz der verstreuten Replikation (interleaved declustering) verfolgt [Te83]. Damit soll vor allem nach Ausfall eines Rechners eine bessere Lastbalancierung erreicht werden als durch vollständige Übernahme einer Partition durch einen zweiten Rechner. Voraussetzung dazu ist, daß die Kopien zu Daten einer Partition auf mehrere andere Knoten verteilt werden. Im Teradata-System ist es dazu möglich, Rechner-Gruppen von jeweils G Knoten zu bilden. Die Kopien zu Daten eines Rechners R werden dann gleichmäßig unter den G-1 anderen Rechnern der Gruppe verteilt, zu der R gehört. Nach Ausfall des Rechners verteilen sich die Zugriffe dann gleichmäßig unter diesen Knoten (sofern eine Gleichverteilung der Zugriffe vorliegt), so daß pro Rechner lediglich eine Mehrbelastung um den Faktor G/G-1 eintritt. Nach einem Rechnerausfall bleiben sämtliche Daten verfügbar; selbst Mehrfachfehler können toleriert werden, solange verschiedene Gruppen betroffen sind, d.h. nicht mehr als ein Knoten pro Gruppe ausfällt. Teradata unterstützt Gruppengrößen von 2 bis 16 Knoten; Relationen können jedoch über mehrere Gruppen verteilt werden (D� G).
Beispiel 17-5
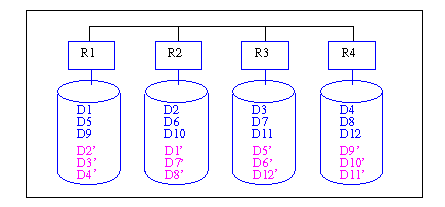
- Abb. 17-7 zeigt ein Beispiel für "Interleaved Declustering" und G=D=4. Die Datenmengen Di bezeichnen dabei einzelne Sätze bzw. Fragmente einer Partition, Di' entspricht der Kopie von Di. Man erkennt, daß die Kopien jeder Partition gleichmäßig über die drei anderen Knoten der Gruppe verteilt sind. Fällt z.B. Rechner R2 aus, so können die Zugriffe auf dessen Daten von den drei überlebenden Rechnern R1, R3 und R4 fortgeführt werden. Erst bei einem weiteren Rechnerausfall kann auf eine Teilmenge der Daten nicht mehr zugegriffen werden
Die Einführung von Gruppen erlaubt einen flexiblen Kompromiß zwischen dem Grad der Lastbalancierung im Fehlerfall und der Datenverfügbarkeit. Denn eine große Gruppe (z.B. G=D) erlaubt eine breite Verteilung der Last des ausgefallenen Rechners. Dafür besteht jedoch eine relativ hohe Wahrscheinlichkeit, daß zwei Rechner gleichzeitig ausfallen, woraufhin dann eine Datenpartition nicht mehr erreichbar ist. Umgekehrt besteht für kleine Gruppen eine sehr hohe Verfügbarkeit, jedoch eine ungünstigere Lastbalancierung. So ergibt sich im Extremfall G=2 das ungünstige Lastbalancierungsverhalten von Spiegelplatten.
Abb. 17-7: Datenverteilung mit verstreuter Replikation (G=D=4)
.
Eine Beschränkung der Teradata-Implementierung liegt darin, daß die Kopien nur im Fehlerfall verwendet werden. Damit wird die Replikation im Gegensatz zu den Spiegelplatten im Tandem-Ansatz also nicht zur Leistungsverbesserung (Lastbalancierung) im Normalbetrieb genutzt. Die effektive Verwendung der Kopien im Normalbetrieb würde von den DBS eine Auswahl der Verarbeitungsrechner unter Berücksichtigung der aktuellen Auslastung erfordern (dynamische Lastbalancierung).
Verkettete Replikation
Der Ansatz der verketteten Replikation (chained declustering), der im Rahmen des Gamma-Projekts untersucht wurde [HD90], versucht die hohe Verfügbarkeit von Spiegelplatten sowie die günstige Lastbalancierung der verstreuten Replikation zu vereinen. Dabei ist es wie bei der verstreuten Replikation möglich, die D Partitionen einer Relation auf mehrere Gruppen von je G Rechnern zu verteilen. Die Datenverteilung innerhalb einer Gruppe erfolgt jetzt jedoch wie in Abb. 17-8 illustriert. Dabei ist die Kopie einer Partition Pi dem jeweils "nächsten" Knoten in der Gruppe, Rj, zugeordnet, wodurch eine logische Verkettung der Knoten entsteht[79]. Der Vorteil liegt darin, daß Mehrfachausfälle in einer Gruppe im Gegensatz zur verstreuten Replikation nicht notwendigerweise die Datenverfügbarkeit reduzieren, sondern nur dann, wenn zwei benachbarte Knoten ausfallen. Fällt z.B. in der Konfiguration von Abb. 17-8 Rechner R2 aus, dann bleiben auch nach Ausfall von R4 alle Daten erreichbar. Wie bei Teradata werden die Kopien Pi' im Normalbetrieb nicht zur Lastbalancierung eingesetzt, sondern nur im Fehlerfall genutzt.
Abb. 17-8: Datenverteilung mit verketteter Replikation (G=D=4)
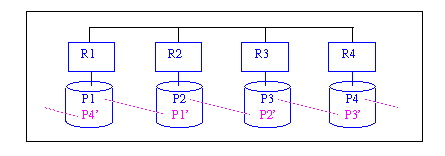
Nach Ausfall eines Rechners mit Partition Pi ist es mit dieser Datenverteilung notwendig, daß der logisch nächste Rechner Rj sämtliche Pi-Zugriffe auf der Kopie Pi' bearbeitet. Damit dadurch nicht eine ähnlich schlechte Lastbalancierung wie bei Spiegelplatten verursacht wird, sieht der Ansatz der verketteten Replikation vor, daß die Lesezugriffe auf den sonstigen Partitionen so unter den verbleibenden Rechnern der Gruppe umverteilt werden, daß sich eine in etwa gleichmäßige Belastung aller Rechner ergibt.
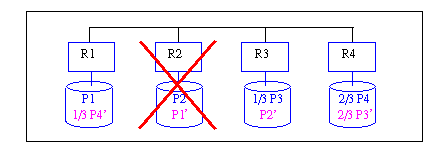
Die prinzipielle Vorgehensweise dazu ist in Abb. 17-9 für das Beispiel aus Abb. 17-8 veranschaulicht. Damit nach dem Ausfall von Rechner R2 eine gleichmäßige Auslastung der verbleibenden drei Rechner erreicht wird, darf die Zugriffshäufigkeit jedes Rechner nur um etwa ein Drittel steigen. Da Rechner R3 bereits sämtliche Zugriffe auf der Kopie von P2, P2', auszuführen hat, werden nun die Zugriffe auf P3 auf R3 und R4 verteilt, so daß nur noch ein Drittel der Zugriffe durch R3 erfolgt und zwei Drittel durch R4 (auf der Kopie P3'). In ähnlicher Weise werden die Zugriffe auf P4 auf die zwei Rechner R4 und R1 verteilt. Diese Änderungen der Zugriffsverteilung erfordern keine Umverteilung der Daten, sondern lediglich eine Anpassung von Verteilungsinformation. So ist in Abb. 17-9 die Partition P3 weiterhin vollständig an den Knoten R3 und R4 gespeichert, und beide Kopien werden bei jeder Änderung aktualisiert. Die Objekte von P3 werden jedoch intern zwei Sub-Partitionen zugeordnet, die ein bzw. zwei Drittel von P3 umfassen. Lesezugriffe auf Objekte der ersten Sub-Partition werden damit von R3, die auf der zweiten Sub-Partition von R4 bearbeitet. Bei einer Gleichverteilung der Zugriffe innerhalb von Partitionen und bei gleicher Zugriffsfrequenz pro Partition kann damit eine gleichmäßige Lastverteilung erreicht werden.
Abb. 17-9: Verkettete Replikation: Lastbalancierung im Fehlerfall
[77] Eine Verallgemeinerung auf mehr als zwei Kopien ist leicht möglich, wird in der Praxis aus Kostengründen jedoch nicht verfolgt.
[78] Der traditionelle Ansatz zur Platten-Recovery über Archivkopien und Archiv-Log erfordert dagegen manuelle Eingriffe und kann zu langen Unterbrechungszeiten führen.
[79] Bei fortlaufender Numerierung der Knoten gilt j = (i MOD G) + 1.