





1 Einführung
Aufgrund der Beschränkungen zentralisierter Datenbanksysteme wurden unterschiedliche Typen sogenannter Mehrrechner-Datenbanksysteme entwickelt, bei denen die Datenbankverwaltungsfunktionen auf mehreren Prozessoren bzw. Rechnern ausgeführt werden. Im folgenden wollen wir einführend auf einige Vertreter von Mehrrechner-Datenbanksystemen eingehen. Genauere Definitionen sowie eine Klassifikation und Abgrenzung der wesentlichen Alternativen erfolgen in Kap. 3.
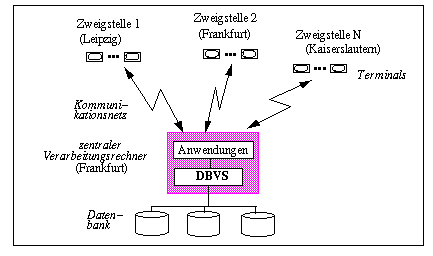
Einen relativ geringen Entwicklungsschritt stellt der Übergang von einem zentralisierten DBS zu Multiprozessor-Datenbanksystemen[2] dar, mit denen die Kapazität von Multiprozessoren zur DB-Verarbeitung genutzt werden kann. Hierzu wird das DBVS i.a. innerhalb mehrerer Prozesse ausgeführt, die vom Betriebssystem dynamisch den Prozessoren zugewiesen werden. Da mit einem solchen Ansatz die meisten Nachteile zentralisierter Datenbanksysteme weiterhin Bestand haben, wird bei den wichtigsten Mehrrechner-DBS die Datenbankverarbeitung auf mehreren unabhängigen Rechnern ausgeführt, die selbst wiederum als Multiprozessoren ausgelegt sein können. Dabei läuft auf jedem der Rechner ein eigenes DBVS; die DBVS kooperieren untereinander, um den Anwendungen gegenüber Aspekte der Verteilung möglichst zu verbergen.
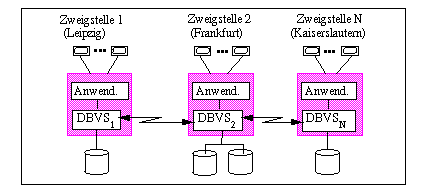
Verteilte Datenbanksysteme [BEKK84, CP84, Da86, ÖV91, BG92] repräsentieren einen bekannten Vertreter solch allgemeinerer Mehrrechner-Datenbanksysteme, sind jedoch nicht mit ihnen gleichzusetzen. Eine wesentliche Eigenschaft Verteilter Datenbanksysteme ist, daß sie eine geographisch verteilte Datenbankverwaltung und damit eine Anpassung an dezentrale Organisationsstrukturen gestatten. Wie im Beispiel von Abb. 1-2 gezeigt, kann somit jeder Zweigstelle einer Bank ein lokales DBVS zugeordnet werden, das die Konto- und Personaldaten der jeweiligen Filiale in einer lokalen Datenbank(partition) hält. Da i.a. die meisten Datenbankzugriffe auf lokale Daten erfolgen, läßt sich ein Großteil der Kommunikationsverzögerungen einsparen. Dennoch kann weiterhin auf die gesamte Datenbank zugegriffen werden, da die DBVS der einzelnen Rechner hierzu miteinander kooperieren. Betrifft ein Datenbankzugriff Daten eines anderen Rechners, wird der entsprechende Auftrag unsichtbar für den Benutzer bzw. das Anwendungsprogramm an diesen weitergeleitet. Der Einsatz mehrerer Verarbeitungsrechner erlaubt eine gesteigerte Leistungsfähigkeit und Verfügbarkeit gegenüber zentralisierten DBS. Der Ausfall eines Rechners betrifft insbesondere lediglich dessen lokale Daten; auf die restliche Datenbank kann weiterhin zugegriffen werden. Nachteilig bei Verteilten Datenbanksystemen ist u.a. die Notwendigkeit einer Systemadministration an jedem Knoten. Weiterhin können Zugriffe auf nicht-lokale Daten zu erheblichen Leistungseinbußen führen, da die Kommunikation in Weitverkehrsnetzen i.a. relativ langsam ist und einen hohen Instruktionsbedarf erfordert (Kap. 2.2).
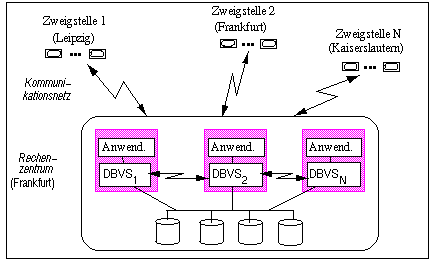
Solche Parallelen DBS erlauben weit bessere Leistungs- und Verfügbarkeitsmerkmale als zentralisierte Datenbanksysteme unter Beibehaltung einer zentralen Administrierbarkeit. Gegenüber Verteilten Datenbanksystemen schlägt neben der einfacheren Systemverwaltung vor allem die Nutzung eines effizienten Kommunikationssystems positiv zu Buche. Dafür ist jedoch eine Anpassung an geographisch verteilte Organisationsstrukturen ("DB-Verarbeitung vor Ort") nicht mehr möglich. Die Bezeichnung "Parallele DBS" rührt daher, daß diese Ansätze die Nutzung von Parallelrechnern mit zahlreichen Prozessoren für die DB-Verarbeitung ermöglichen. Dabei soll auch eine Parallelverarbeitung innerhalb von Transaktionen bzw. DB-Anfragen unterstützt werden.
Mehrrechner-Datenbanksysteme stellen nicht die einzige Möglichkeit einer verteilten Transaktionsbearbeitung dar. Diese kann nämlich auch außerhalb des DBVS realisiert werden, z.B. indem Anwendungen und DBVS auf getrennten Rechnern ablaufen. Eine solche Systemstruktur findet sich häufig in Client/Server-Umgebungen, wenn Anwendungsprogramme von Workstations und PCs auf entfernte Datenbanken von Server-Rechnern zugreifen. Die Realisierungsalternativen zur verteilten Transaktionsverarbeitung werden in Kap. 11 behandelt.