




Mehrrechner-Datenbanksysteme
9 Replizierte Datenbanken
Hauptziel beim Einsatz replizierter Datenbanken ist die Steigerung der Verfügbarkeit eines Verteilten DBS. Denn repliziert an mehreren Knoten gespeicherte Daten bleiben auch nach Ausfall eines der Rechner erreichbar. Daneben wird auch eine Verbesserung der Leistungsfähigkeit angestrebt, insbesondere für Lesezugriffe. So lassen sich viele Kommunikationsvorgänge einsparen, indem man Objekte repliziert an allen Knoten speichert, an denen sie häufig referenziert werden (Unterstützung von Lokalität). Zum anderen erhöht die Wahlmöglichkeit unter mehreren Kopien das Potential zur Lastbalancierung, so daß die Überlastung einzelner Rechner eher vermeidbar ist. Unter diesen Gesichtspunkten bieten natürlich voll-redundante Datenbanken, bei denen jeder Knoten eine Kopie der gesamten Datenbank führt, die größten Vorteile; insbesondere können prinzipiell alle Lesezugriffe lokal abgewickelt werden.
Beispiel 9-1
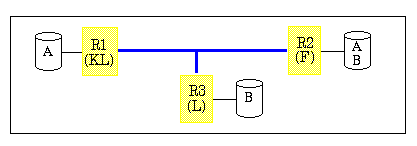
- In der Bankanwendung seien die Konten unter den einzelnen Filialen partitioniert, zusätzlich sei jeder Kontosatz in der Bankzentrale in Frankfurt repliziert gespeichert (Abb. 9-1). Dies unterstützt zum einen eine lokale Verarbeitung in den jeweiligen Zweigstellen; zudem können in der Zentrale Auswertungen über mehrere Filialen hinweg lokal berechnet werden. Weiterhin kann nach Ausfall eines Rechners (prinzipiell) weiterhin auf alle Konten zugegriffen werden.
Abb. 9-1: Beispiel replizierter Datenhaltung
Allerdings verursacht das Führen replizierter Daten nicht nur einen erhöhten Speicherplatzbedarf, sondern v.a. hohe Änderungskosten, um alle Replikate bei einer Modifikation zu aktualisieren. Dieser Aktualisierungsaufwand ist in ortsverteilten Systemen wegen der teuren Kommunikation besonders hoch, so daß in der Regel nur eine partielle Replikation in Betracht kommt. Replizierte Datenbanken führen ferner zu einer signifikanten Erhöhung der Implementierungskomplexität von Verteilten DBS, da die Existenz von Replikaten dem Benutzer gegenüber transparent gehalten werden soll (Replikationstransparenz). Das DBS hat somit dafür zu sorgen, daß Änderungen automatisch auf alle Kopien übertragen werden, damit diese untereinander konsistent bleiben. Weiterhin sollte den Transaktionen auch eine konsistente Version der Daten zur Verfügung stehen. Hierzu sind Erweiterungen im Synchronisationsprotokoll erforderlich, um zu verhindern, daß Leser unterschiedliche Änderungszustände zu sehen bekommen und daß Replikate eines Objektes gleichzeitig von mehreren Transaktionen geändert werden.
Die genannten Anforderungen werden von erweiterten Synchronisationsverfahren erfüllt, die das Korrektheitskriterium der 1-Kopien-Serialisierbarkeit (one copy serializability) [BHG87] unterstützen. Diese lassen nur solche Schedules zu, welche zu serialisierbaren Schedules auf einer nicht-redundanten Datenbank äquivalent sind. Das DBS muß weiterhin dafür sorgen, daß die DB-Konsistenz auch im Fehlerfall gewahrt bleibt, insbesondere nach Netzwerk-Partitionierungen. Denn wenn z.B. in einem Hotelreservierungssystem mit replizierter Datenhaltung eine Netzwerk-Partitionierung auftritt, könnte es ohne Zusatzmaßnahmen vorkommen, daß zwei Kunden dasselbe Zimmer für dieselbe Nacht buchen. Schließlich verlangt die Unterstützung replizierter Datenbanken Erweiterungen im physischen Datenbankentwurf sowie bei der Query-Optimierung und -Verarbeitung.
In diesem Kapitel stellen wir die drei wichtigsten Verfahrensklassen zur Aktualisierung von und Synchronisation auf replizierten Datenbanken vor: sogenannte Write-All-Ansätze (Kap. 9.1), Primary-Copy-Verfahren (Kap. 9.2) sowie Voting-Ansätze (Kap. 9.3). Danach gehen wir noch auf zwei speziellere Ansätze zur Unterstützung replizierter Datenbanken ein, welche von einigen kommerziellen DBS bereits verwendet werden. Dies sind der Einsatz von sogenannten DB-Schnappschüssen (Kap. 9.4) sowie die Nutzung einer DB-Kopie zur Katastrophen-Recovery (Kap. 9.5). Der Einsatz von Datenreplikation in lokal verteilten Mehrrechner-DBS (Parallelen DBS) wird in Kap. 17.4 diskutiert.
- 9.1 - Write-All-Ansätze
-
- 9.2 - Primary-Copy-Verfahren
-
- 9.3 - Voting-Verfahren
-
- 9.4 - Schnappschuß-Replikation
-
- 9.5 - Katastrophen-Recovery
-
- 9.6 - Abschließende Bemerkungen
-
- Übungsaufgaben
-