




Mehrrechner-Datenbanksysteme
12 Föderative Datenbanksysteme
Die vorgestellten Ansätze der programmierten Verteilung sowie der Verteilung von DB-Operationen gestatten eine weitgehende Heterogenität und Autonomie der LDBS. Praxisorientierte Standardisierungsanstrengungen der X/Open und SAG erlauben die Verwendung einer gemeinsamen SQL-Anfragesprache auf unterschiedlichen DBS. Einschränkungen der Autonomie einzelner LDBS betreffen vor allem die Transaktionsverwaltung, z.B. durch die Unterstützung der XA-Schnittstelle zur verteilten Commit-Behandlung nach X/Open DTP. Außerdem kann innerhalb einer DB-Operation nicht auf mehrere Datenbanken zugegriffen werden, und es besteht nur ein geringer Grad an Verteilungstransparenz. Insbesondere wird keine Unterstützung zur Behandlung semantischer Heterogenität geboten.
Föderative Mehrrechner-DBS streben eine Behebung der letztgenannten Einschränkungen an. Unter föderativen Mehrrechner-DBS (FDBS) verstehen wir eine Menge autonomer, möglicherweiser heterogener LDBS, welche in begrenztem Umfang kooperieren, um externen Benutzern einen kontrollierten Zugriff auf Teile ihrer Daten zu gestatten. Dabei sollten die erwähnten Nebenanforderungen wie Verteilungstransparenz, Verbergen der Heterogenität (einheitliche Anfragesprache, einheitliches Datenmodell, automatische Behandlung von semantischer Heterogenität), DB-Operationen auf mehreren Datenbanken sowie das Transaktionskonzept möglichst erfüllt werden.
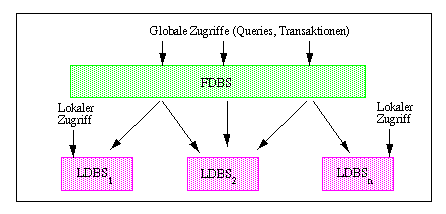
Die Architektur von FDBS basiert i.a. auf einem Zusatzebenen-Ansatz, da die LDBS weitgehend unverändert bleiben sollen (Abb. 12-1). Aufgabe der Zusatzschicht "FDBS" ist es, in der gemeinsamen Anfragesprache formulierte globale Anfragen bzw. Transaktionen, welche mehrere LDBS betreffen, zu bearbeiten. Hierzu erfolgt eine Zerlegung dieser Anfragen in von den LDBS lokal ausführbare Teilanfragen sowie (für Leseoperationen) das Zusammenführen der Teilergebnisse. Damit kann dann z.B. auch eine verteilte Join-Berechnung über unabhängige Datenbanken erfolgen. Die Zusatzschicht umfaßt daneben weitere globale Aufgaben, etwa zur Transaktionsverwaltung. Die Realisierung der Zusatzebene kann zentralisiert oder verteilt erfolgen. So könnte auf jedem LDBS-Knoten auch eine FDBS-Komponente vorliegen, die mit den FDBS-Komponenten anderer Rechner kommuniziert. Alternativ dazu ist eine FDBS-Ausführung auf dedizierten Rechnern möglich.
Abb. 12-1: Grobarchitektur von föderativen DBS
Bei der Realisierung von föderativen DBS lassen sich grob zwei Klassen unterscheiden, die wir nach [SL90] als eng bzw. lose gekoppelte FDBS bezeichnen wollen. Eng gekoppelte FDBS streben eine weitgehende Verteilungstransparenz an, in dem Benutzern gegenüber ein globales konzeptionelles Schema bzw. föderatives Schema angeboten wird, welches die Existenz mehrerer LDBS verbirgt. Dies setzt eine sogenannte Schemaintegration (s.u.) voraus, während der auch eine Behandlung von semantischer Heterogenität erfolgt. Die LDBS können sich im allgemeinen Fall zu mehreren Föderationen, mit jeweils einem eigenen föderativen Schema, zusammenschließen, um unterschiedlichen Benutzergruppen verschiedene Sichtweisen auf die Datenbanken zu ermöglichen. Bei lose gekoppelten FDBS dagegen, welche häufig auch als Multi-DBS bezeichnet werden, wird keine Schemaintegration angestrebt. Vielmehr bleibt hier die Unterscheidung mehrerer Datenbanken für den Benutzer sichtbar. Er bekommt jedoch Hilfsmittel (insbesondere eine Anfragesprache) zur Verfügung gestellt, um in einfacher und mächtiger Weise auf die verschiedenen Datenbanken zuzugreifen.
Im nächsten Unterkapitel betrachten wir zunächst eine allgemeine Schemaarchitektur für FDBS, welche eng und lose gekoppelte FDBS abdeckt. Anschließend stellen wir unterschiedliche Formen der semantischen Heterogenität sowie den Prozeß der Schemaintegration vor. Danach wird die Nutzung lose gekoppelter FDBS diskutiert. Abschließend behandeln wir kurz die Transaktionsverwaltung in FDBS. Überblicke zu FDBS-Prototypen bzw. -Produkten finden sich u.a. in [LMR90, Th90, BHP92].
- 12.1 - Schemaarchitektur
-
- 12.2 - Semantische Heterogenität
-
- 12.3 - Schemaintegration
-
- 12.4 - Einsatz einer Multi-DB-Anfragesprache
-
- 12.5 - Transaktionsverwaltung
-
- Übungsaufgaben
-