




18.2 Parallelisierung unärer relationaler Operatoren
18.2.1 Selektion
Die Selektion (Restriktion) ist der mit Abstand am häufigsten auszuführende Operator, so daß seiner Parallelisierung eine besonders hohe Bedeutung für die Leistungsfähigkeit eines Parallelen DBS zukommt. Kann die Suchbedingung durch einen Index auf eine Teilmenge der Relation eingegrenzt werden, spricht man von einem Index-Scan; im Extremfall wird kein oder nur ein Tupel referenziert (z.B. Exact-Match-Anfrage auf dem Primärschlüssel). Anderenfalls ist ein Relationen-Scan erforderlich, der den Zugriff auf jedes Tupel der Relation erfordert. Im folgenden betrachten wir die Parallelisierung für die verschiedenen Architekturtypen.
Für Shared-Nothing ist die Parallelisierung der Selektion sehr einfach und durch die Datenverteilung bestimmt. Denn wenn eine Relation horizontal in die n Partitionen R1, R2, ... Rn aufgeteilt ist, gilt:
- R =
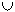 Ri (1
Ri (1 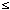 i
i 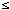 n)
n)
und
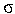 p (R) =
p (R) = 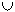
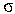 p(Ri) (1
p(Ri) (1 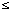 i
i 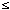 n).
n).
Die Selektion kann also parallel auf den n Datenknoten der Relation, denen jeweils eine Partition zugeordnet ist, durchgeführt werden. Das Gesamtergebnis ergibt sich durch die anschließende Vereinigung der n Teilergebnisse. Im Falle einer Hash- oder Bereichsfragmentierung lassen sich bestimmte Anfragen auf dem Verteilattribut auf eine Teilmenge der Rechner beschränken (s. Kap. 17.2). Alle anderen Selektionen sind jedoch auf sämtlichen n Datenknoten auszuführen, auch im Falle eines Index-Scans. Der Index-Scan reduziert in diesem Fall lediglich die pro Partition auszuwertende Satzmenge, jedoch nicht die Kommunikationskosten zum Starten der n Teilanfragen, zum Zurücksenden der Teilergebnisse sowie zur Teilnahme am Commit-Protokoll. Für selektive Anfragen kann dieser Kommunikationsaufwand im Vergleich zur eigentlichen Nutzarbeit sehr ungünstig werden.
Bei Shared-Everything und Shared-Disk ist die Parallelisierung von Selektionsoperationen auf die Datenverteilung auf Platte abzustimmen, um zu verhindern, daß parallel auszuführende Teilselektionen auf die selben Platten zugreifen (Kap. 17.5). Der große Vorteil im Vergleich zu Shared-Nothing liegt darin, daß der Parallelitätsgrad durch die Datenverteilung noch nicht vorgegeben ist. Vielmehr kann dieser je nach Anfragetyp oder Systemauslastung variiert werden. So können selektive Anfragen zur Minimierung des Parallelisierungs-Overheads stets sequentiell auf einem Prozessor bearbeitet werden. Relationen-Scans dagegen lassen sich problemlos auf mehreren Prozessoren parallel bearbeiten, wobei die Datenverteilung (Anzahl der Platten, auf denen die Relation allokiert wurde) lediglich den maximalen Parallelitätsgrad vorgibt. Im Gegensatz zu Shared-Nothing, wo Selektionsoperationen auf Basisrelationen stets auf den Datenknoten ausgeführt werden, sind bei Shared-Everything und Shared-Disk die ausführenden Rechner nicht durch die Datenverteilung vorbestimmt, sondern frei wählbar. Dies ergibt insbesondere hohe Freiheitsgrade zur dynamischen Lastbalancierung.
Beispiel 18-1
- Die KONTO-Relation einer Bank sei über 25 Partitionen (Platten) verteilt; ferner sei ein Index auf KTONR und KNAME (Kundenname) definiert. Exact-Match-Anfragen zu beiden Attributen können für Shared-Everything und Shared-Disk auf jeweils einem Prozessor und der minimalen Plattenanzahl bearbeitet werden. Bei Shared-Nothing erfordert dagegen der Zugriff über KNAME die Involvierung aller Rechner, falls die Datenverteilung über KTONR definiert wurde (Beispiel 17-2). Selbst im Falle einer zweidimensionalen Bereichsfragmentierung sind bei Shared-Nothing mehrere Knoten zu involvieren (im Mittel 5 nach Beispiel 17-4), so daß ein deutlich höherer Kommunikationsaufwand entsteht. Relationen-Scans, z.B. um die Summe aller Kontostände zu berechnen, können auch bei Shared-Disk und Shared-Everything parallel auf allen Platten durchgeführt werden.
Shared-Everything erlaubt einen geringeren Overhead zum Starten der Teilanfragen und zum Mischen der Teilergebnisse als Shared-Disk und Shared-Nothing. Dafür ist dort der Parallelitätsgewinn durch die i.a. recht geringe Prozessoranzahl beschränkt. Für Shared-Disk kann gegenüber Shared-Nothing ggf. Kommunikationsaufwand eingespart werden, indem Teilergebnisse nicht über Nachrichten zurückgeliefert, sondern in temporären Dateien auf den gemeinsamen Platten (bzw. in einem gemeinsamen Halbleiter-Speicherbereich) abgelegt werden. Dies empfiehlt sich für große Ergebnismengen, die im Empfangsrechner nicht vollständig im Hauptspeicher gehalten werden können, so daß eine Speicherung auf Externspeicher ohnehin erforderlich ist. Für kleinere Zwischenergebnisse ist dagegen auch bei Shared-Disk die Rücklieferung über das Kommunikationssystem vorzuziehen.