




18.2 Parallelisierung unärer relationaler Operatoren
 A(R) =
A(R) = 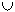
 A(Ri) (1
A(Ri) (1 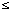 i
i 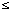 n).
n).Die Projektion verlangt ggf. eine Eliminierung von Duplikaten, die i.a. durch Sortieren der Ergebnismenge erfolgt (s.u.). Alternativ dazu kann die Erkennung von Duplikaten hash-basiert erfolgen [Gra93]. Dabei wird jedes Tupel über eine Hash-Funktion in eine Hash-Tabelle abgebildet. Die Erkennung von Duplikaten beschränkt sich damit auf die Tupel einer Hash-Klasse, was bei wenigen Tupeln pro Hash-Klasse (sehr viele Hash-Klassen) billig möglich ist. Durch Aufteilung der Hash-Klassen unter mehrere Prozessoren kann die Duplikateliminierung zudem leicht parallelisiert werden.