




18.4 Probleme der parallelen DB-Verarbeitung
18.4.1 Skew-Behandlung
Die effektive Parallelisierung einer Operation in mehrere Teilanfragen verlangt, daß jede Teilanfrage möglichst gleich schnell bearbeitet wird, da die gesamte Bearbeitungszeit durch die langsamste Teiloperation bestimmt ist. Die Varianz in den Bearbeitungszeiten, die wir als Ausführungs-Skew (execution skew) bezeichnen, ist jedoch oft nur schwer zu begrenzen und beeinträchtigt somit Speedup und Skalierbarkeit (Abb. 18-9). Ausführungs-Skew geht vielfach auf Daten-Skew zurück, der vorliegt, wenn einzelne Teiloperationen unterschiedlich große Datenmengen zu verarbeiten haben. Daten-Skew wiederum ist oft eine Folge ungleicher Werteverteilungen in der Datenbank (attribute value skew [WDJ91]). In der folgenden Diskussion unterstellen wir Einbenutzerbetrieb, wo die Umgehung von Ausführungs-Skew bereits ein großes Problem darstellt. Im Mehrbenutzerbetrieb verschärfen sich die Skew-Probleme, da das damit einhergehende Ausmaß an Behinderungen zwischen Transaktionen an verschiedenen Rechnern i.a. differiert.
Abb. 18-9: Einfluß von Ausführungs-Skew
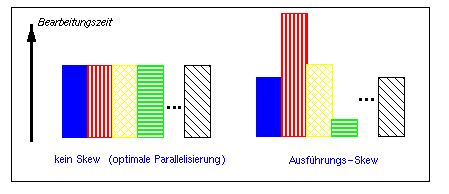
Der Einsatz von Pipeline-Parallelität (Inter-Operatorparallelität) ist besonders anfällig für Ausführungs-Skew, da die von einzelnen Operatoren zu verarbeitenden Datenmengen stark differieren können. Die Datenmengen sind zudem durch die konkreten Datenbankinhalte und Anfragecharakteristika bestimmt, welche von der Anfrageoptimierung jedoch nicht beeinflußbar und deren Auswirkungen auf die Größe von Zwischenergebnisse oft nur ungenau abschätzbar sind.
Im Falle von Datenparallelität (Intra-Operatorparallelität) äußert sich Daten-Skew meist in der Form von Partitions-Skew, der vorliegt, wenn Teiloperationen unterschiedlich große Datenpartitionen bearbeiten, die statisch oder dynamisch definiert sein können. Für parallele Join-Verfahren (Kap. 18.3) kann sich Partitions-Skew in der Scan-Phase, während der dynamischen Umverteilung sowie in der Join-Phase negativ bemerkbar machen. Dabei können nach [WDJ91] insgesamt vier Arten von Partitions-Skew unterschieden werden, die auch kombiniert auftreten können:
- Datenverteilungs-Skew (tuple placement skew)
Die statische Datenverteilung unter mehreren Rechnern (bzw. Platten) führte zu unterschiedlich großen Partitionen, so daß Leseoperationen (Scans) darauf unterschiedlich lange andauern. Bei Definition der Datenverteilung auf einem Verteilungsattribut (Hash- bzw. Bereichsfragmentierung, Kap. 17.2) kann dies durch eine ungleichmäßige Werteverteilung für dieses Attribut und/oder eine ungeeignete Verteilungsfunktion hervorgerufen werden.
- Selektivitäts-Skew
Die Scan-Operationen auf den einzelnen Partitionen weisen unterschiedliche Selektivitätsfaktoren auf, so daß sich unterschiedlich viele Tupel qualifizieren. Ein Beispiel hierfür ist etwa eine Bereichsanfrage auf dem Verteilungsattribut.
- Umverteilungs-Skew (redistribution skew)
Die dynamische Umverteilung der Ergebnisse der Scan-Phase führt zu unterschiedlich großen Join-Operanden für verschiedene Join-Prozesse. Dies ist möglich aufgrund einer schiefen Werteverteilung für das Join-Attribut und/oder einer ungeeigneten Verteilungsfunktion zur dynamischen Partitionierung der Daten.
- Join-Produkt-Skew
Die Join-Selektivität differiert zwischen den Join-Knoten, so daß sich unterschiedlich viele Sätze für das Join-Ergebnis qualifizieren.
Selektivitäts-Skew kann dynamisch kaum beeinflußt werden, da er durch die jeweilige Anfrage sowie die gewählte Datenverteilung bestimmt ist. Voraussetzung zur Vermeidung von Datenverteilungs- und Umverteilungs-Skew ist eine möglichst genaue Kenntnis der Werteverteilung für das Attribut, auf dem die Verteilungsfunktion anzuwenden ist. Die Häufigkeit bestimmter Attributwerte kann entweder vollständig in Form von Histogrammen geführt oder stichprobenartig über Sampling-Verfahren ermittelt werden. Zur Definition der statischen Datenverteilung empfiehlt sich die Nutzung von Histogrammen, welche durch Lesen aller Sätze ermittelt und im Katalog gespeichert werden können. Durch Definition einer auf die Werteverteilung abgestimmten Bereichspartitionierung kann dann Datenverteilungs-Skew umgangen werden, insbesondere wenn der Primärschlüssel als Verteilattribut gewählt wird (keine replizierten Attributwerte).
Für die dynamische Umverteilung kann die Werteverteilung i.a. vorab nicht abgeschätzt werden, so daß sie dynamisch zu ermitteln ist. Der Aufwand hierfür ist relativ gering für Sort-Merge-Joins, wenn bereits vor der Umverteilung eine Sortierung an den Datenknoten erfolgt. Die Werteverteilung kann dann nämlich während des Sortierens bestimmt und an einem ausgezeichneten Knoten für alle Datenknoten kombiniert werden (ähnlich wie für parallele Sortierverfahren, Kap. 18.2.4). Anderenfalls muß über ein Sampling-Ansatz eine Approximation der Werteverteilung bestimmt werden. Der Aufwand hierfür kann nach [DNSS92] relativ gering gehalten werden, jedoch ist eine effektive Stichprobenerhebung erst möglich, wenn die umzuverteilenden Datenmengen vollständig vorliegen [Gra93]. Dies impliziert, daß Pipeline-Parallelität zwischen Scan- und Join-Phase nicht mehr nutzbar ist.
Umverteilungs-Skew läßt sich bei (in Annäherung) bekannter Werteverteilung für das Join-Attribut auch wieder am besten durch eine Verteilung über eine Bereichspartitionierung erreichen [DNSS92], da hiermit in etwa gleich große Partitionsgrößen gebildet werden können. Weiterhin läßt sich auch der Extremfall, daß das gehäufte Auftretens eines einzigen Wertes zu Skew führt, behandeln, während eine Hash-Funktion alle Sätze mit übereinstimmenden Join-Attributwert dem gleichen Join-Rechner zuordnet. Die Lösung besteht darin, Tupel mit dem betreffenden Join-Attributwert w mehreren Join-Knoten zuzuordnen (überlappende Bereiche), so daß die einzelnen Partitionen in etwa die gleiche Größe annehmen. In diesem Fall muß jedoch darauf geachtet werden, das vollständige Join-Ergebnis zu erhalten. Eine Möglichkeit besteht darin, die Sätze der ersten Relation mit Join-Attributwert w unter mehreren Join-Rechnern zu partitionieren und die zugehörigen Sätze der zweiten Relation an den betreffenden Join-Rechnern zu replizieren (d.h. an alle Join-Rechner mit w-Sätzen der ersten Relation zu schicken). Der umgekehrte Ansatz ist, die w-Sätze der ersten Relation zu replizieren und die der zweiten Relation zu partitionieren.
Beispiel 18-2
- Für die folgenden Relationen R und S soll der Join über Attribut B an zwei Join-Prozessoren berechnet werden.
| R (A, B) | S (B, C) |
| (1, 3) | (1, 1) |
| (2, 3) | (2, 2) |
| (3, 3) | (3, 3) |
| (4, 4) | (4, 4) |
| | (5, 4) |
- Es wird entschieden, daß die Tupel im Wertebereich 1-3 für B dem ersten, und im Bereich 3-5 dem zweiten Join-Prozessor zugeordnet werden, so daß der Join-Attributwert 3 zwei Prozessoren zugeordnet wird. Eine Partitionierungsmöglichkeit von R hierzu ist, die R-Tupel (1, 3) und (2, 3) dem ersten und die Tupel (3, 3) und (4, 4) dem zweiten Join-Prozessor zuzuordnen. In diesem Fall ist das S-Tupel (3, 3) zu replizieren, also beiden Join-Prozessoren zuzuweisen, um das vollständige Join-Resultat zu erhalten.
Das Ausmaß von Join-Produkt-Skew ist durch die Werteverteilung des Join-Attributs beider Relationen bestimmt, wie sie sich im Join-Ergebnis niederschlägt. Eine Bereichspartitionierung der beiden Eingaberelationen in je p etwa gleich große Partitionen (p = Anzahl der Join-Prozessoren) reicht daher zur Vermeidung dieses Skew-Typs nicht aus, da der Umfang der Join-Ergebnisse für den einzelnen Partitionen stark schwanken kann. Die Lösung erfordert vielmehr eine Abschätzung der Gesamtgröße des Join-Ergebnisses sowie der dabei entstehenden Werteverteilung für das Join-Attribut, welche aus der Werteverteilung für die Eingaberelationen abgeleitet werden kann. Damit läßt sich dann eine Bereichspartitionierung festlegen, welche für jeden der p Join-Prozessoren ein etwa gleich großes Teilergebnis ergibt. Problematisch ist dabei vor allem wieder der Fall, wenn aufgrund stark ungleicher Werteverteilung ein einzelner Attributwert zur Überlastung eines Join-Prozessors führt. Solche Werte sind dann von mehreren Join-Prozessoren zu bearbeiten, wobei wieder für eine der Relationen eine Partitionierung, für die andere eine Replizierung der entsprechenden Sätze an die zuständigen Join-Rechner notwendig wird. Zur Balancierung der Last ist es hierzu auch oft erforderlich, mehr Partitionen (Bereiche) als Join-Prozessoren zu bilden und jedem Prozessor mehrere Partitionen zuzuweisen [DNSS92].
Beispiel 18-3
- Es soll ein Join zwischen zwei Relationen mit je 10.000 Sätzen bestimmt werden, wobei Join-Attributwert w in beiden Relationen 1000-mal vorkommen soll, alle übrigen Werte dagegen nur einmal. Für den Wert w ergeben sich somit 1 Million Resultats-Tupel, gegenüber höchstens 9000 Ergebnistupel für die anderen Werte. Bei 10 Join-Prozessoren ist einer somit hoffnungslos überlastet, wenn jeder Join-Attributwert nur einem Rechner zugeordnet wird (wie bei einer Hash-Funktion der Fall). Auch eine Bereichspartitionierung mit einer Aufteilung der Relationen in 10 Bereiche ergibt den gleichen Effekt, da die w-Tupel nur 1/10 der Sätze ausmachen und somit einer Partition (einem Join-Rechner) zugewiesen werden. Zur Lösung des Problems müssen die w-Tupel offenbar von allen 10 Join-Prozessoren bearbeitet werden, so daß für den Attributwert w bereits wenigstens 10 Partitionen vorzusehen sind. Für die Zuordnung der anderen Werte sind nochmals mindestens 10 Wertebereiche erforderlich, so daß also jedem Join-Prozessor wenigstens 2 Partitionen zugewiesen werden. Die 1000 w-Sätze der ersten Relation können somit unter den 10 Join-Prozessoren partitioniert werden, während die 1000 w-Sätze der zweiten Relation an jeden Join-Prozessor gehen. Damit umfaßt das Teilergebnis jedes Join-Prozessors 100.000 w-Tupel, wie zur Lastbalancierung bzw. Vermeidung von Join-Produkt-Skew erforderlich.