




18.4 Probleme der parallelen DB-Verarbeitung
Ein noch weitgehend ungelöstes Problem ist jedoch die effektive Parallelisierung komplexer DB-Anfragen für heterogene bzw. gemischte Lasten, wenn parallel zu einer Anfrage andere Anfragen bzw. OLTP-Transaktionen im System auszuführen sind. Die Unterstützung solcher Arbeitslasten ist bereits für zentralisierte DBS ein großes Problem, da es zwischen den Lasttypen zu Interferenzen kommt, welche das Leistungsverhalten empfindlich beeinträchtigen können. Behinderungen zeigen sich sowohl für Datenobjekte im Rahmen der Synchronisation (data contention) als auch für allgemeine Betriebsmittel wie CPU, Platten, Hauptspeicher, etc., um die konkurriert wird (resource contention). So sind etwa zahlreiche Sperrkonflikte vorprogrammiert, wenn komplexe Anfragen lange Lesesperren halten, die parallel vorzunehmende Änderungen blockieren und somit den OLTP-Durchsatz reduzieren. Eine Abhilfemöglichkeit hierfür besteht in der Nutzung eines Mehrversionen-Sperrverfahrens, womit für lesende Transaktionen bzw. Anfragen Synchronisationskonflikte vermieden werden (Kap. 8.4).
Problematischer ist die Behandlung von Resource-Contention aufgrund des hohen Ressourcenbedarfs komplexer Anfragen, der zu starken Behinderungen gleichzeitig aktiver Transaktionen führen kann. Hier besteht im wesentlichen nur die Möglichkeit, durch geeignete Scheduling-Verfahren die Behinderungen zu kontrollieren. So kann OLTP-Transaktionen, deren zügige Bearbeitung in vielen Anwendungen oberstes Ziel sein muß, eine höhere Priorität als komplexen Anfragen eingeräumt werden, um die Behinderungen für sie einzuschränken. Allerdings werden solche Prioritäten in derzeitigen DBS noch kaum unterstützt. Ferner ist für die Wirksamkeit der Priorisierung wesentlich, daß Scheduling-Komponenten im DBS, Betriebssystem oder dem TP-Monitor die gleichen Prioritäten verwenden, was eine Kooperation zwischen diesen Subsystemen erfordert, die in derzeitigen Systemen nicht vorliegt [Ra93a].
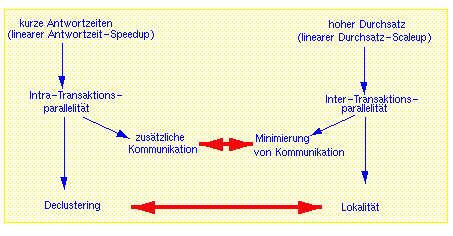
Die Probleme mit gemischten Lasten verschärfen sich bei paralleler DB-Verarbeitung auf einem Mehrrechner-Datenbanksystem. Dies liegt daran, daß die gleichzeitige Unterstützung hoher Transaktionsraten für OLTP und kurzen Antwortzeiten für komplexe Anfragen hier weitere Zielkonflikte (Tradeoffs) verursacht, die zum Teil in Abb. 18-10 illustriert sind. So ist zur Erlangung kurzer Antwortzeiten für komplexe Anfragen Intra-Transaktionsparallelität erforderlich, die jedoch zwangsweise einen höheren Kommunikationsaufwand als eine sequentielle Bearbeitung hervorruft. Dies führt zu einer Verschärfung der Interferenzen mit gleichzeitig laufenden Transaktionen. Die Notwendigkeit dieser gleichzeitig aktiven Transaktionen ergibt sich aus der Forderung nach hohem Durchsatz, insbesondere für OLTP-Transaktionen. Denn dieser kann nur mit Inter-Transaktionsparallelität (Mehrbenutzerbetrieb) erzielt werden, da bei serieller Transaktionsausführung aufgrund von E/A- oder Kommunikationsunterbrechungen eine inakzeptable CPU-Auslastung entstünde. Die Erlangung hoher Transaktionsraten verlangt zudem die Minimierung des Kommunikations-Overheads, um die effektive CPU-Nutzung zu optimieren, was jedoch im Widerspruch zu der durch Intra-Transaktionsparallelität verursachten Zunahme des Kommunikations-Overhead steht.
Im verteilten Fall ist es zur Kontrolle von Resource-Contention im Mehrbenutzerbetrieb auch wesentlich, den Parallelitätsgrad und damit das Ausmaß an Behinderungen zwischen Transaktionen dynamisch an die aktuelle Lastsituation anzupassen. So kann für komplexe Anfragen bei geringer Systemauslastung ein hoher Parallelitätsgrad toleriert werden, während im Hochlastfall oft ein geringerer Grad an Intra-Transaktionsparallelität sinnvoll ist. Eine weitere Forderung dabei ist die Unterstützung einer dynamischen Lastbalancierung, um eine möglichst gleichmäßige Rechnerauslatung zu erreichen. Dazu sollten Transaktionen bzw. einzelne Teilanfragen möglichst Rechnern mit geringer Auslastung zugewiesen werden.
Für beide Kontrollentscheidungen bieten Shared-Disk und Shared-Everything wiederum die höchsten Freiheitsgrade, da Parallelitätsgrad sowie ausführende Prozessoren durch die Datenverteilung nicht vorgegeben sind. Dies ist jedoch bei Shared-Nothing der Fall für Zugriffe auf Basisrelationen, so daß hierfür keine dynamischen Steuerungsmöglichkeiten bestehen. Shared-Nothing bietet diese lediglich für Operationen (z.B. Joins) auf abgeleiteten Daten, die dynamisch umverteilt werden, so daß die Anzahl der Zielrechner sowie deren Auswahl zur Laufzeit festgelegt werden können (Kap. 18.3.2).
Eine Leistungsbewertung verschiedener Verfahren zur dynamischen Parallelisierung und Lastbalancierung für Shared-Nothing findet sich in [RM93, RM95]. Die Untersuchungen konzentrieren sich auf die parallele Join-Verarbeitung und berücksichtigen die aktuelle CPU- und Hauptspeicherauslastung für dynamische Kontrollentscheidungen. In [RS95] wird die parallele Bearbeitung von Scan-Anfragen in Shared-Disk-Systemen analysiert. Es stellt sich u.a. heraus, daß durch eine dynamische Festlegung des Parallelitätsgrades Plattenengpässe reduziert werden können, was bei Shared-Nothing für Scan-Anfragen nicht möglich ist.