Mehrrechner-Datenbanksysteme
Die Bestimmung einer Datenbankverteilung kann nach einem Top-Down- oder einem Bottom-Up-Ansatz erfolgen. Der Bottom-Up-Ansatz eignet sich vor allem, wenn mehrere existierende Datenbanken integriert werden sollen. Dabei werden dann insbesondere die einzelnen lokalen konzeptionellen Schemata (LKS) zu einem gemeinsamen konzeptionellen Schema (GKS) zusammengefaßt. Dieser Ansatz kommt vor allem im Kontext von föderativen DBS in Frage und wird daher in Kap. 12 weiterbetrachtet. Beim Top-Down-Ansatz dagegen liegt bereits ein GKS einer logischen Datenbank vor. Hier gilt es zu entscheiden, wie die Objekte (Relationen) des GKS auf die einzelnen Rechner und deren LKS verteilt werden.
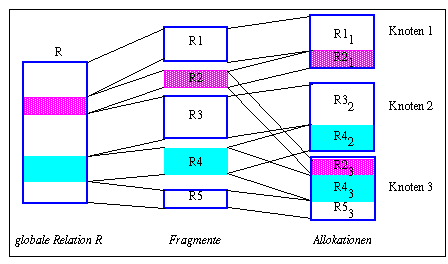
Diese Aufgabe läßt sich in zwei Teilprobleme untergliedern: Fragmentierung und Allokation. Im Rahmen der Fragmentierung werden dabei zunächst die Einheiten der Datenverteilung (Fragmente) festgelegt. In relationalen Datenbanken kommen hierzu vor allem eine zeilenweise (horizontale) oder spaltenweise (vertikale) Fragmentierung in Betracht. Die Allokation (Ortszuweisung) bestimmt danach, welchem Rechner jedes der Fragmente zugeordnet wird, wobei eine replizierte Alllokation von Fragmenten möglich ist. Dieser zweistufige Abbildungsprozeß wird durch Abb. 5-1 veranschaulicht. Dabei wird die im GKS definierte globale Relation R zunächst in mehrere Fragmente zerlegt. Danach erfolgt die möglicherweise replizierte Allokation dieser Fragmente zu Rechnern. Im Beispiel wird so eine Zerlegung in fünf Fragmente vorgenommen, von denen für zwei (R2, R4) eine replizierte Allokation stattfindet. Die Menge der einem Rechner zugeordneten Fragmente einer globalen Relation ergeben dessen lokale Relation; z.B. umfaßt die an Knoten 2 vorliegende lokale Relation die Fragmente R3 und R4. Die DB-Partition eines Rechners besteht aus der Menge seiner lokalen Relationen.