




8.5 Deadlock-Behandlung
8.5.4 Deadlock-Erkennung
Bei der Deadlock-Erkennung (detection) werden sämtliche Wartebeziehungen aktiver Transaktionen explizit in einem Wartegraphen (wait-for graph) protokolliert und Verklemmungen durch Zyklensuche in diesem Graphen erkannt. Im Gegensatz zum Serialisierungs- oder Abhängigkeitsgraphen sind im Wartegraphen nur aktive Transaktionen berücksichtigt, die an einem Sperrkonflikt beteiligt sind. Die Auflösung eines Deadlocks geschieht durch Rücksetzung einer oder mehrerer der am Zyklus beteiligten Transaktionen. Die Deadlock-Erkennung ist zwar im Vergleich zu Vermeidungs- oder Timeout-Strategien am aufwendigsten, dafür kommt sie mit den wenigsten Rücksetzungen aus. Dies bewirkte in quantitativen Untersuchungen [ACM87] die beste Leistungsfähigkeit für zentralisierte DBS, wo die Deadlock-Erkennung auch relativ einfach realisiert werden kann [ACD83, Ji88].
Beispiel 8-16
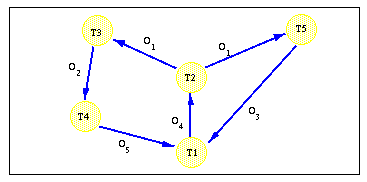
- Abb. 8-10 zeigt ein Beispiel eines Wartegraphen. Die Kanten zwischen den Transaktionen sind mit dem Objekt gekennzeichnet, für das der Konflikt auftrat. Für die Sperranforderung von T2 auf Objekt O1 ist ein Konflikt mit zwei Transaktionen entstanden (die z.B. beide eine Lesesperren halten). In dem gezeigten Szenario liegen zwei Deadlocks vor:
T1 -> T2 -> T3 -> T4 -> T1 sowie T1 -> T2 -> T5 -> T1. Die Rücksetzung von T2 würde beide Deadlocks auflösen.
Abb. 8-10: Beispiel eines Wartegraphen
Die Zyklensuche kann bei jedem Sperrkonflikt vorgenommen werden (continous deadlock detection) oder in periodischen Zeitabständen. Im ersteren Fall wird ein Deadlock zum frühestmöglichen Zeitpunkt aufgelöst; zudem vereinfacht sich die Suche, da i.a. nur ein Teil des Graphen zu berücksichtigen ist. Bei der periodischen Zyklensuche ist stets der ganze Graph zu durchsuchen, dafür kann der Aufwand durch eine seltenere Ausführung begrenzt werden. Allerdings ergibt sich dann wieder eine verzögerte Auflösung von Deadlocks ähnlich wie bei einem Timeout-Ansatz. Bei der Auswahl der "Opfer" können verschiedene Kriterien herangezogen werden, z.B. Minimierung des Arbeitsverlustes oder Einfachheit der Opferbestimmung. Wird bei einem Sperrkonflikt jeweils sofort eine Deadlock-Erkennung vorgenommen, kann ein neuer Deadlock einfach durch Rücksetzung der in den Konflikt geratenen Transaktion umgangen werden. Dies ist im verteilten Fall jedoch nicht mehr möglich.
Die Deadlock-Erkennung in Verteilten DBS ist weitaus aufwendiger als in zentralisierten DBS, da Kommunikationsvorgänge zur Mitteilung von Wartebeziehungen notwendig werden. Zudem ist es schwierig, überhaupt eine korrekte Deadlock-Erkennung zu realisieren, da jeder Knoten nur bezüglich lokaler Transaktionen die aktuelle Wartesituation kennt. Warteinformationen bezüglich externer Transaktionen sind dagegen aufgrund zeitlicher Verzögerungen bei der Übertragung i.a. veraltet. So konnte für viele Verfahrensvorschläge gezeigt werden, daß sie "falsche" Deadlocks (Phantom-Deadlocks) erkennen und somit Transaktionen zurücksetzen, ohne daß ein Deadlock vorliegt [BHG87]. Vielfach werden auch globale Deadlocks mehrfach erkannt, was ebenfalls zu unnötigen Rücksetzungen führt.
Im folgenden diskutieren wir verschiedene Ansätze zur globalen Deadlock-Erkennung, die entweder zentral oder verteilt erfolgen kann.
Zentrale Deadlock-Erkennung
Hierbei wird in einem zentralen Knoten ein globaler Wartegraph geführt und auf Zyklen durchsucht. Um den Kommunikations-Overhead einzugrenzen, schickt jeder Rechner die bei ihm entstehenden Wartebeziehungen in periodischen Zeitabständen an den zentralen Knoten (Nachrichtenbündelung). Dieser vervollständigt damit seinen Wartegraph und startet die Zyklensuche. Da der globale Wartegraph wegen der Nachrichtenverzögerungen i.a. nicht auf dem aktuellsten Stand ist, werden Deadlocks nicht nur verspätet entdeckt, es können auch Phantom-Deadlocks erkannt und damit unnötige Rücksetzungen verursacht werden. Die Sonderrolle des für die Deadlock-Erkennung zuständigen Rechners bewirkt zudem ähnliche Probleme bezüglich Verfügbarkeit und Rechnerautonomie wie bei einem zentralen Sperrverfahren. Nach einem Ausfall des zentralen Knotens könnte jedoch leicht ein anderer dessen Funktion übernehmen bzw. auf ein Timeout-Verfahren umgestellt werden.
Eine zentrale Deadlock-Erkennung wurde in Distributed Ingres vorgenommen [St79].
Verteilte Deadlock-Erkennung
Eine verteilte Deadlock-Erkennung vermeidet die Abhängigkeiten zu einem zentralen Knoten, ist dafür jedoch wesentlich schwieriger zu realisieren. Insbesondere kann es zur Mehrfacherkennung globaler Deadlocks kommen und Warteinformationen sind ggf. über mehrere Rechner zu propagieren, bis ein globaler Deadlock erkannt wird. Ein Überblick zu den zahlreichen Verfahrensvorschlägen findet sich in [El86, Kn87]. Wir beschränken uns hier auf die Beschreibung des im System R* implementierten Verfahrens von Obermarck [Ob82, MLO86]. Es hat den großen Vorteil, daß lediglich eine Nachricht benötigt wird, um globale Deadlocks aufzulösen, an denen zwei Rechner beteiligt sind. Dies ist der wichtigste Typ von globalen Deadlocks, da typischerweise die meisten Deadlocks (> 90%) nur Zykluslänge 2 aufweisen [GHOK81]. Eine zentrale Deadlock-Erkennung hätte bereits zur Übertragung der Wartebeziehungen einen höheren Aufwand erfordert.
Das Obermarck-Verfahren geht davon aus, daß in jedem Rechner ein spezieller Prozeß ("deadlock detector") mit der Deadlock-Erkennung beauftragt ist und mit den entsprechenden Prozessen der anderen Rechner kommuniziert. Jeder dieser Prozesse führt einen lokalen Wartegraphen, in dem sämtliche Wartebeziehungen lokaler und externer Transaktionen hinsichtlich der an diesem Rechner verwalteten Objekte geführt werden. Damit lassen sich lokale Deadlocks sofort und ohne Kommunikation erkennen. Im Wartegraph wird ein spezieller Knoten EXTERNAL geführt, der Wartebeziehungen zu Sub-Transaktionen auf anderen Rechnern kennzeichnet. Für eine externe Sub-Transaktion Tj wird stets eine Wartebeziehung EXTERNAL -> Tj aufgenommen, da möglicherweise an anderen Rechnern auf Sperren von Tj gewartet wird. Eine Wartebeziehung Ti -> EXTERNAL wird ferner eingeführt, sobald Transaktion Ti eine externe Sub-Transaktion startet, da diese möglicherweise in einen Konflikt gerät. Ein potentieller globaler Deadlock wird durch einen Zyklus im lokalen Wartegraphen angezeigt, an dem der EXTERNAL-Knoten beteiligt ist:
EXTERNAL -> T1 -> T2 -> ... -> Tn -> EXTERNAL
Um festzustellen, ob tatsächlich ein globaler Deadlock vorliegt, wird die Warteinformation an den Rechner weitergeleitet, an dem Transaktion Tn die Sub-Transaktion gestartet hatte. Nach Empfang solcher Warteinformationen vervollständigt der zuständige Prozeß seinen Wartegraphen und führt darauf eine Zyklensuche durch. Zur Erkennung eines globalen Deadlocks kann dazu erneut die Weiterleitung der erweiterten Warteinformation an einen anderen Rechner erforderlich sein. Wird ein vollständiger Zyklus festgestellt, erfolgt die Rücksetzung einer der beteiligten Transaktionen. Dabei sollte, wenn möglich, eine lokale Transaktion ausgewählt werden, um den Deadlock möglichst schnell zu beheben [MLO86].
Ein Problem mit dem skizzierten Verfahren liegt darin, daß sich im Falle eines globalen Deadlocks an jedem der beteiligten Rechner ein Zyklus mit dem EXTERNAL-Knoten ergibt. Wenn jetzt jeder dieser Rechner seine Warteinformation zur globalen Deadlock-Erkennung wie oben beschrieben weitergibt, führt dies jedoch zu einem unnötig hohen Kommunikationsaufwand sowie zur mehrfachen Erkennung eines globalen Deadlocks. Zur Abschwächung dieses Problems wird jeder Transaktion T wiederum eine global eindeutige Zeitmarke ts (T) mitgegeben. Die Weiterleitung der Warteinformation in obiger Situation wird damit nur dann vorgenommen, wenn ts (Tn) < ts (T1) gilt. Damit wird bei einem globalen Deadlock mit zwei Rechnern gewährleistet, daß nur einer der beiden Rechner die Warteinformation weiterleitet. Bei mehr als zwei Rechnern ist es jedoch weiterhin möglich, daß ausgehend von mehr als einem Rechner die Warteinformation weitergegeben wird.
Beispiel 8-17
- Für den in Abb. 8-8 gezeigten Deadlock (Beispiel 8-11) bildet sich in Rechner R1 folgender Zyklus
- EXTERNAL -> T2 -> T1 -> EXTERNAL,
in R2 dagegen
- EXTERNAL -> T1 -> T2 -> EXTERNAL.
- Wenn ts (T1) < ts (T2) gilt, dann sendet lediglich R1 seine Warteinformation an R2, nicht jedoch umgekeht. In R2 wird der Wartegraph vervollständigt und der Zyklus
- T1 -> T2 -> T1
entdeckt. Der Deadlock wird durch Rücksetzen der lokalen Transaktion T2 aufgelöst.
Der Obermarck-Algorithmus benötigt maximal N * (N-1) / 2 Nachrichten für einen sich über N Rechner erstreckenden globalen Deadlock. Für N=2 fällt also lediglich eine Nachricht an. Allerdings kann es zur Erkennung "falscher" Deadlocks kommen, da die Wartegraphen der einzelnen Rechner i.a. unterschiedliche Änderungszustände reflektieren [El86].
- Zentrale Deadlock-Erkennung
-
- Verteilte Deadlock-Erkennung
-