13 Architektur von Shared-Disk-DBS
Wesentlich für eine hohe Leistungsfähigkeit sowie Skalierbarkeit von SD-Systemen ist, daß eine große Anzahl von Rechnern mit allen Platten verknüpft werden kann. In konventionellen E/A-Subsystemen, wie sie etwa in IBM-Großrechner-Konfigurationen vorliegen, bestehen jedoch diesbezüglich relativ enge Grenzen. Diese Architekturen sind durch Platten und Platten-Controller gekennzeichnet, die jeweils nur eine feste Anzahl von Zugriffspfaden erlauben. In der Regel kann dabei eine bestimmte Platte von zwei Controllern aus erreicht werden; ein Platten-Controller ist meist nur an bis zu 8 bis 16 E/A-Prozessoren anschließbar, die wiederum einem Rechner fest zugeordnet sind. Damit sind solche Shared-Disk-Konfigurationen auf maximal 16 Rechnerknoten beschränkt. Dies stellt für Großrechner, welche selbst wiederum aus mehreren Prozessoren bestehen können, meist keine signifikante Einschränkung dar. Allerdings sind damit hohe Systemkosten und vergleichsweise geringe Kosteneffektivität vorgegeben.
Die Alternative besteht in einem nachrichtenbasierten E/A-Subsystem, bei dem E/A-Prozessoren und Platten-Controller über ein allgemeines Verbindungsnetzwerk gekoppelt sind und über Nachrichtenaustausch kommunizieren. Damit werden auch sämtliche Seitentransfers zwischen Haupt- und Externspeicher im Rahmen von Nachrichten abgewickelt. Ein solcher Ansatz ermöglicht eine prinzipiell unbeschränkte Anzahl von Rechnerknoten, wobei auch preisgünstige Mikroprozessoren verwendet werden können. Allerdings wird ein sehr leistungsfähiges und skalierbares Übertragungsnetzwerk erforderlich, dessen Kapazität mit der Rechneranzahl wächst.
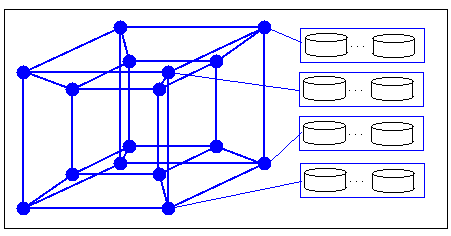
Die VaxCluster-Systeme von DEC [KLS86] verfolgten als erstes eine solche nachrichtenbasierte E/A-Schnittstelle, wobei bis zu 96 Rechner und Platten-Controller miteinander verknüpft werden können. Höhere Rechneranzahlen verlangen i.d.R. mehrstufige Verbindungsnetzwerke, um ein skalierbares Leistungsverhalten zu erreichen. Beispiele hierfür sind Hypercube-Konfigurationen, welche aus 2N Rechnerknoten bestehen, wobei jeder Knoten nur mit N Nachbarn direkt verbunden ist. Zur Kommunikation sind somit ggf. Zwischenknoten zu involvieren; die maximale Distanz zwischen zwei Knoten ist jedoch auf N begrenzt. Die Anzahl der Verbindungen und damit die Übertragungskapazität steigt proportional mit der Rechneranzahl. Wie in Abb. 13-2 gezeigt, kann die Plattenanbindung dadurch realisiert werden, daß N der Knoten als Platten-Controller fungieren, unter denen alle Platten aufgeteilt werden. Da diese N Knoten von allen restlichen Rechnern erreichbar sind, kann von jedem Knoten aus auf sämtliche Platten zugegriffen werden. Allerdings ergeben sich dabei i.a. langsamere Zugriffszeiten als bei direkter Plattenanbindung ohne Zwischenknoten.
Neben den Magnetplatten können auch weitere Externspeicher von allen Rechnern genutzt werden. Insbesondere sind durch die Controller verwaltete Platten-Caches für alle Knoten zugreifbar, wodurch sich das E/A-Verhalten durch Einsparung von Plattenzugriffen verbessern läßt. Denn jede im Platten-Cache gepufferte Seite vermeidet das Lesen von Platte. Bei nicht-flüchtigen Platten-Caches, die i.a. über eine Reservebatterie realisiert werden, können zudem auch Schreibzugriffe stark optimiert werden [Ra92a]. Ähnliche Performance-Gewinne können mit anderen seitenadressierbaren Halbleiterspeichern wie Solid-State-Disks erzielt werden. Die im Vergleich zu Platten hohen Kosten solcher Speicher dürften sich in Shared-Disk-Systemen eher als in zentralisierten Systemen amortisieren.