





16 Einführung in Parallele DBS
Wesentlich für die Kosteneffektivität von Parallelen DBS ist der weitgehende Verzicht auf Spezial-Hardware, da diese i.a. hohe Kosten verursacht. Stattdessen sollte soweit wie möglich Standard-Hardware zum Einsatz kommen, insbesondere weit verbreitete Mikroprozessoren für die CPUs. Durch die software-mäßige Parallelisierung der DB-Verarbeitung können dann sowohl die geringen Kosten als auch die enormen Leistungssteigerungen der Standard-Hardware (Mikroprozessoren) unmittelbar genutzt werden. Dieser Aspekt wurde bei der Realisierung älterer DB-Maschinen ignoriert und ist Hauptgrund für deren geringe Relevanz (Kap. 3.3). Eine software-basierte Parallelisierung kann jedoch durchaus innerhalb eines auf DB-Verarbeitung beschränkten Back-End-Systems (DB-Maschine, Server) erfolgen (Beispiele: Teradata, IBM Parallel Query Server). Für OLTP-Anwendungen auf allgemeinen Verarbeitungsrechnern kann dies jedoch zu hohen Kommunikationskosten führen, wenn jede (einfache) DB-Operation eine Kommunikation mit dem Back-End-System erfordert. Für Anfragen, die große Ergebnismengen zurückliefern, entsteht ebenfalls ein hoher Kommunikationsaufwand mit dem Back-End-System, wenn die Ergebnisse satzweise abgerufen werden.
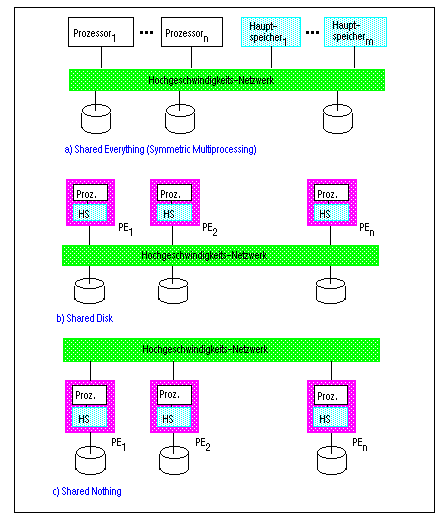
Intra-Transaktionsparallelität wurde bisher vor allem für Shared-Everything- (Multiprozessoren) und für Shared-Nothing-Systeme untersucht sowie innerhalb von Prototypen und kommerziellen DBS realisiert. Die Nutzung von Multiprozessoren zur Parallelverarbeitung kann dabei als erster Schritt aufgefaßt werden, da er i.a. auf relativ wenige Prozessoren begrenzt ist (Kap. 3.1). Die Verwendung eines gemeinsamen Hauptspeichers erleichtert dabei die Parallelisierung, da eine effiziente Kommunikation zwischen Prozessen einer Transaktion und eine einfachere Lastbalancierung möglich wird. Prototyp-Realisierungen paralleler Shared-Everything-DBS sind u.a. XPRS [SKPO88], Volcano [Gra94] und DBS3 [ZZB93]. Auch kommerzielle DBS nutzen zunehmend Multiprozessoren für Intra-Transaktionsparallelität, z.B. DB2 [Ha90] oder Informix [Dav92].
Shared-Nothing-Systeme, aber auch Shared-Disk-Systeme, bieten eine größere Erweiterbarkeit als Shared-Everything, so daß eine entsprechend weitergehende Parallelisierung unterstützt werden kann. Bei der Realisierung lokal verteilter Shared-Nothing-DBS können viele der Konzepte von Verteilten DBS übernommen werden, z.B. zur Transaktionsverarbeitung (Commit-Behandlung, Synchronisation). Dabei ergibt sich aufgrund der schnelleren Kommunikation i.a. eine effizientere Bearbeitung als im ortsverteilten Fall[70]. Bezüglich der Katalog- und Namensverwaltung spielt die Wahrung einer hohen Knotenautonomie keine Rolle mehr, so daß einfachere Lösungen möglich werden. Zum Beispiel kann eine vollständige Replikation der Katalogdaten vorgesehen werden. Notwendige Erweiterungen zur Unterstützung von Intra-Transaktionsparallelität betreffen vor allem die Bestimmung der Datenverteilung sowie die Anfragebearbeitung; darauf wird in diesem Kapitel ausführlich eingegangen. Intra-Transaktionsparallelität wird bereits seit mehreren Jahren in den beiden Shared-Nothing-Systemen Teradata (Kap. 19.8) und Tandem NonStop-SQL (Kap. 19.7) unterstützt; neuere Entwicklungen bestehen für Sybase (Kap. 19.6) und DB2/6000 (Kap. 19.1.3). Daneben verfolgen zahlreiche Prototypen den Shared-Nothing-Ansatz, z.B. Gamma [De90], Bubba [Bo90], EDS [Sk92], Prisma [Ap92] und Arbre [LY89].
Demgegenüber stehen die Untersuchungen zur Intra-Transaktionsparallelität in Shared-Disk-Systemen noch am Anfang [Ra93e]. Existierende Implementierungen sind bisher weitgehend auf Inter-Transaktionsparallelität beschränkt. Eine initiale Unterstützung von Intra-Transaktionsparallelität auf Basis von Oracles "Parallel Server" (Kap. 19.2.2) wurde für den KSR1-Parallelrechner (Kendall Square) realisiert [RMW93]. In der allgemeinen Produktversion 7.1 ist ebenfalls eine beschränkte Form von Intra-Transaktionsparallelität vorgesehen. Daneben wird in dem neuen IBM Shared-Disk-System Parallel Query Server für DB2 (Kap. 19.1.3) eine Parallelisierung von SQL-Anfragen unterstützt.
Parallele DBS müssen nicht nur Verarbeitungsparallelität, sondern auch E/A-Parallelität unterstützen, insbesondere um große Datenmengen parallel von mehreren Platten einzulesen. Dies setzt auch in Shared-Everything- und Shared-Disk-DBS eine entsprechende Verteilung der Daten (Relationen) über mehrere Platten voraus. Dies kann transparent für das DBS erfolgen, und zwar innerhalb sogenannter Disk-Arrays, welche in der jüngsten Vergangenheit starke Bedeutung erreicht haben [PGK88, Ra93a, WZ93]. Disk-Arrays bestehen intern aus mehreren Platten, können jedoch logisch wie eine Platte angesprochen werden, so daß ihr Einsatz prinzipiell keine Änderungen in der nutzenden Software erfordert. Durch den Einsatz von E/A-Parallelität soll das Leistungsverhalten gegenüber einzelnen Platten jedoch deutlich verbessert werden. Ferner sind automatische Methoden zur Fehlerbehandlung vorgesehen, um eine hohe Ausfallsicherheit zu gewährleisten. Ein weiterer Vorteil liegt in der Verwendung kleiner Platten (z.B. mit einem Durchmesser von 3,5 Zoll), welche eine verbesserte Kosteneffektivität gegenüber großen Platten aufweisen. Der Kostenvorteil wird jedoch durch die Notwendigkeit spezialisierter Platten-Kontroller wieder kompensiert, welche für die Organisation der E/A-Parallelität sowie die Fehlerbehandlung verantwortlich sind.
Die Realisierung Paralleler DBS mit solchen Disk-Arrays wurde bisher noch nicht ausreichend untersucht und ist zumindest problematisch. Denn außerhalb des DBS kann eine Datenverteilung nur auf physischen Objektgranulaten wie Blöcken erfolgen. Wünschenswert dagegen wäre eine logische Definition der Datenverteilung über Datenwerte, um so die Bearbeitung bestimmter Operationen auf eine Teilmenge der Platten begrenzen zu können. Ferner kann eine Parallelisierung ohne genaue Kenntnis der Datenverteilung dazu führen, daß parallele Teiloperationen auf dieselben Platten zugreifen und somit E/A-Engpässe erzeugt werden[71]. Zudem stellen Disk-Arrays Spezial-Hardware dar und weisen eine Reihe weiterer Probleme für die DB-Verarbeitung auf (z.B. ist die Erzeugung von Archivkopien sehr problematisch) [GHW90]. Wir werden daher diesen Ansatz hier nicht weiter betrachten, sondern annehmen, daß die Verteilung der Daten über mehrere Platten den DBVS bekannt ist und über Datenbankwerte definiert werden kann.