





18.2 Parallelisierung unärer relationaler Operatoren
Da die Sortierung in vielen DBS die teuerste Operation überhaupt ist, stellt sie einen besonders geeigneten Kandidaten zur Parallelisierung dar. Zur Nutzung von Datenparallelität sollte dabei die Eingabe bereits über mehrere Partitionen/Rechner verteilt sein (multiple input). Ebenso ist nach [LY89] eine Partitionierung der sortierten Ausgabe (multiple output) sehr wichtig, um die Verzögerung zur Erzeugung eines sequentiellen Ausgabestromes zu vermeiden. Ferner sollten die Sortier- und Mischphasen parallel abgewickelt werden. Zur Reduzierung des Kommunikationsaufwandes sollte dazu jedes Tupel höchstens einmal über das Netzwerk verschickt werden [Gra93]. In der folgenden Diskussion unterstellen wir eine Shared-Nothing-Architektur. Eine Übertragung der Ansätze auf Shared-Disk und Shared-Everything ist jedoch leicht möglich.
Ein einfacher Ansatz zur parallelen Sortierung einer partitionierten Relation sieht vor, die Partitionen an den Datenknoten parallel einzulesen und lokal zu sortieren. Danach werden die so erzeugten Läufe an einen einzigen Mischknoten geschickt, wo durch Mischen das sortierte Gesamtergebnis erzeugt wird. Dieser Ansatz hat jedoch den offensichtlichen Nachteil, daß nur die erste Phase parallel arbeitet, während das Mischen sowie die Ergebnisausgabe sequentiell an einem Knoten erfolgen. Dieser Nachteil kann durch folgenden Ansatz behoben werden.
Dabei erfolgt zunächst wieder das parallele Einlesen und Sortieren der verschiedenen Partitionen der Relation, die dann jedoch unter mehrere Mischknoten aufgeteilt werden[80]. Diese dynamische Datenumverteilung durch Verschicken der Tupel wird über eine (dynamische) Bereichspartitionierung auf dem Sortierattribut gesteuert. Dabei wird für p Mischprozessoren der Wertebereich des Sortierattributs vollständig in p disjunkte Intervalle zerlegt, so daß etwa gleich viel Tupel pro Intervall entfallen. Ein Tupel, dessen Sortierattributwert dem i-ten Intervall angehört, wird dann an den i-ten Mischknoten geschickt. Damit enthält jeder Mischprozessor alle Tupel des ihm zugeordneten Wertebereichsintervalls. Die einzelnen Mischknoten mischen die bei ihnen eingehenden Tupelströme parallel und unterstützen eine partitionierte Ausgabe an den Benutzer. Dabei wird zunächst das sortierte Ergebnis des ersten Mischprozessors bereitgestellt, dann das des zweiten usw. Der Algorithmus, der parallel in allen Phasen arbeitet, ist in Abb. 18-1 veranschaulicht. Dabei wurde die Sortierung auf einem Namensattribut unterstellt. Nicht gezeigt sind Plattenzugriffe für temporäre Dateien, die sowohl an den Daten- als auch an den Mischknoten notwendig werden können.
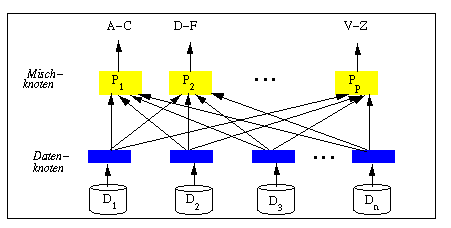
Die Beschreibung der parallelen Sortierung verdeutlicht, daß die sequentiellen Basisoperatoren für Sortieren und Mischen in den Daten- und Mischknoten weiterhin zur Anwendung kommen. Die Parallelisierung basiert zum einen auf der partitionierten Datenverteilung zum Lesen der Eingabedaten und zum anderen auf der dynamischen Datenumverteilung zur Parallelisierung des Mischvorgangs. Eine sehr ähnliche Vorgehensweise kann auch zur Parallelisierung anderer Operatoren angewendet werden, insbesondere zur Join-Berechnung (s.u.). Damit ist es auch relativ einfach möglich, aus einem sequentiellen einen parallelen Ausführungsplan zu erzeugen. Im Gamma-System genügten so im wesentlichen zwei zusätzliche Operatoren, Split und Merge, zur Realisierung der parallelen Query-Bearbeitung [DG92]. Die Split-Operation realisiert die Aufteilung eines Datenstromes in mehrere Teilmengen, die verschiedenen Rechnern bzw. Prozessen zugeordnet werden, z.B. über eine Bereichs- oder Hash-Fragmentierung gesteuert. Die Merge-Operation nimmt dagegen das Mischen mehrerer Datenströme vor, die z.B. durch zuvor ausgeführte Operatoren auf verschiedenen Partitionen einer Relation erzeugt werden. Im Volcano-System sind die Split- und Merge-Funktionen durch einen einzigen Operator, dem sogenannten Exchange-Operator, realisiert [Gra94].