





18.3 Parallele Joins
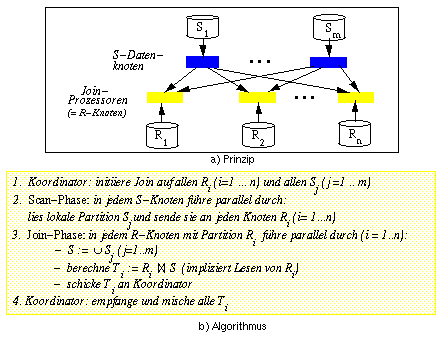
Der Ansatz verursacht offenbar einen sehr hohen Kommunikationsaufwand, da jede S-Partition vollständig an n Rechner zu schicken ist. Dieser Aufwand steigt proportional mit dem R-Verteilungsgrad n sowie der S-Größe und kann somit für große Relationen extrem teuer werden. Zudem entsteht ein hoher Join-Aufwand, da in jedem R-Knoten ein Verbund mit der vollständigen S-Relation vorzunehmen ist. Der Hauptvorteil liegt darin, daß der Ansatz für beliebige Join-Bedingungen anwendbar ist, also nicht nur für Equi-Joins. Die lokale Join-Berechnung in Schritt 3 kann prinzipiell mit jedem sequentiellen Ansatz erfolgen, wobei jedoch für Nicht-Equi-Joins i.a. ein Nested-Loop-Join notwendig wird [ME92][82]. Der Ansatz der dynamischen Replikation wird daher gelegentlich auch als paralleler Nested-Loop-Join bezeichnet [ÖV91].
Der Algorithmus nutzt Datenparallelität zum parallelen Einlesen der R- und S-Partitionen sowie zur parallelen Join-Berechnung in den R-Knoten. Daneben läßt sich Pipeline-Parallelität zwischen der Scan- und der Join-Phase vorteilhaft einsetzen, insbesondere wenn ein Nested-Loop-Ansatz zur lokalen Join-Berechnung zur Anwendung kommt. Denn das Verschicken einzelner S-Tupel an die R-Rechner kann unmittelbar nach Bearbeitung an den Datenknoten erfolgen, ohne daß also zuvor die gesamte S-Partition gelesen wurde. Ebenso kann die Join-Berechnung in den R-Knoten mit eingehenden S-Tupeln sofort durchgeführt werden, ohne daß auf das Eintreffen aller S-Sätze gewartet wird. Darüber hinaus können neu berechnete Tupel des Verbundergebnisses direkt an den Koordinatorknoten weitergeleitet werden. Die Nutzung der Pipeline-Parallelität reduziert auch die Notwendigkeit, Daten in temporären Dateien zwischenzuspeichern, und erlaubt somit E/A-Einsparungen.
Für Shared-Everything kann die Replikation der S-Partition sowie die Kommunikation für Datenumverteilungen entfallen, da Tupel der S-Relation im gemeinsamen Hauptspeicher von allen Prozessoren referenziert werden können. Es genügt somit ein einmaliges Einlesen der S-Tupel, wobei die S-Tupel parallel mit den n R-Partitionen abgeglichen werden. Wenn das mehrfache Lesen eines S-Tupels verhindert werden soll, muß es solange gepuffert bleiben, bis der Vergleich mit allen R-Partitionen beendet ist. Bei annähernd gleichmäßigem Fortgang der Verarbeitung in den Join-Prozessen dürfte der zur S-Pufferung benötigte Speicherumfang relativ gering gehalten werden können. Der eigentliche Join-Aufwand ist für Shared-Everything so hoch wie für Shared-Nothing, da jede R-Partition mit der vollständigen S-Relation zu vergleichen ist.
Auch für Shared-Disk kann die aufwendige Kommunikation zur Datenumverteilung prinzipiell umgangen werden, da jeder Prozessor direkt auf die S-Platten zugreifen kann. Allerdings erfolgt für Shared-Disk das Lesen von Platte bei nachrichtenbasierter E/A-Schnittstelle auch durch Kommunikation zwischen den Verarbeitungsrechnern sowie E/A-Prozessoren (Platten-Controllern). So kommt die in Abb. 18-2a skizzierte Vorgehensweise auch für Shared-Disk zur Anwendung, wobei lediglich E/A-Prozessoren an die Stelle der S-Datenknoten treten. Der Unterschied zu Shared-Nothing besteht darin, daß dort die S-Datenknoten "aktiv" sind und S-Tupel zur Weiterverarbeitung an die Join-Rechner schicken. Die E/A-Prozessoren bei Shared-Disk dagegen sind "passiv" und liefern die S-Tupel (S-Seiten) erst nach Aufforderung (Lese-E/A) durch die Join-Rechner. Das n-fache Lesen der S-Relation dürfte jedoch ähnlich teuer sein wie die Datenumverteilung bei Shared-Nothing.
Der gleichzeitige Zugriff auf die S-Relation durch mehrere Join-Prozessoren birgt für Shared-Disk zudem die Gefahr von Plattenengpässen. Diese Problem kann durch gezielte Nutzung von Platten-Caches in den E/A-Prozessoren abgeschwächt werden, ähnlich wie durch den gemeinsamen Hauptspeicher bei Shared-Everything. Der E/A-Prozessor liest dabei idealerweise die S-Tupel lediglich einmal von Platte und puffert sie im Platten-Cache, bis alle Join-Prozessoren die S-Tupel angefordert haben. Der Vorteil des Shared-Disk-Ansatzes gegenüber Shared-Nothing liegt darin, daß an den Join-Rechnern ein Zwischenspeichern von S-Tupeln in temporären Dateien definitiv vermieden werden kann. Bei Shared-Nothing dagegen kann dies notwendig werden, wenn die S-Tupel schneller an die Join-Rechner geliefert als sie dort verarbeitet werden. Außerdem ist die Anzahl der Join-Rechner für Shared-Disk prinzipiell frei wählbar, während sie bei Shared-Nothing durch den R-Verteilungsgrad n festgelegt ist.