4 Architektur von Verteilten Datenbanksystemen
Zur Unterstützung von Verteilungstransparenz ist es wünschenswert, daß Benutzer die für zentralisierte DBS gültigen Namenskonventionen weiterhin benutzen können. Zentralisierte SQL-Implementierungen verwenden oft eine zweiteilige Namensstruktur für DB-Objekte[14] (Relationen, Sichten, ...), bei der ein logischer Objektname folgendermaßen aufgebaut ist:
Dabei sind sämtliche DB-Objekte dem erzeugenden Benutzer zugeordnet. Die Angabe des Benutzernamens ist nur für Zugriffe auf Objekte eines anderen Benutzers erforderlich. Dieser Ansatz ermöglicht, daß verschiedene Benutzer Objekte mit dem gleichen Objektnamen erzeugen können.
Im (geographisch) verteilten Fall garantiert diese Namensstruktur jedoch keine globale Eindeutigkeit von Objektbezeichnungen, da Benutzernamen i.a. nicht systemweit eindeutig sind. Prinzipiell läßt sich dieses Problem dadurch beheben, indem auf das globale konzeptionelle Schema (GKS) zugegriffen wird, um die Eindeutigkeit eines Objektnamens sicherzustellen. Dies ist am ehesten möglich bei einem Name-Server-Ansatz, bei dem sämtliche Namen des GKS (sowie die physische Lokation der Objekte) an einer zentralen Stelle geführt werden. Dies entspricht einer zentralisierten Katalogverwaltung und verursacht wiederum Kommunikationsverzögerungen zur Namensvergabe und verletzt die Knotenautonomie. Ähnlich problematisch ist die vollständige Replikation des GKS, vor allem bei hoher Rechneranzahl. Denn hierbei sind die durch Erzeugen neuer Objekte bedingten Änderungen des GKS systemweit zu synchronisieren und zu propagieren.
Die Alternative besteht in einem hierarchischen Namenskonzept, bei dem die Objektbezeichnungen zur Erlangung globaler Eindeutigkeit um Knotennamen erweitert werden. Wir bezeichnen solchermaßen erweiterte, systemweit eindeutige Bezeichnungen als globale Objektnamen. Eine mögliche Struktur globaler Objektnamen sieht folgendermaßen aus[15]:
Dabei sei <Knotenname> die Bezeichnung des Rechners, an dem das Objekt erzeugt wurde ("birth site") [Li81]. Ist dieser Name nicht spezifiziert, wird defaultmäßig der Rechner verwendet, an dem die betreffende DB-Operation gestartet wird. Damit kann für lokal erzeugte Objekte die Angabe von Objektnamen wie im zentralen Fall erfolgen. Insbesondere braucht bei der Erzeugung eines neuen Objektes kein Knotenname angegeben werden; zudem läßt sich die globale Eindeutigkeit bereits mit dem lokalen Katalog überprüfen. Für den Zugriff auf nicht-lokale Objekte ist jedoch die Spezifizierung des Knotennamens erforderlich, was Zusatzmaßnahmen zur Gewährleistung von Verteilungstransparenz verlangt (s.u.).
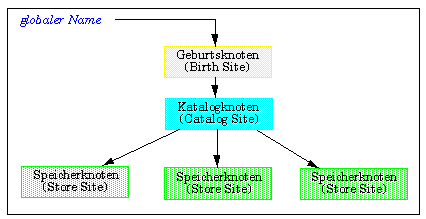
Insgesamt sind drei Arten von Knoten bei der Verwaltung und Speicherung von Objekten beteiligt (Abb. 4-4): der Knoten, an dem ein Objekt erzeugt wurde (birth site), der (oder die) Knoten, an dem Katalogdaten zu dem Objekt verwaltet werden (catalog site), und schließlich die Knoten, an denen das Objekt gespeichert ist (store site). Es handelt sich dabei um eine logische Sichtweise, da ein einzelner Knoten durchaus die verschiedenen Funktionen auf sich vereinen kann (was zur Reduzierung von Kommunikationsvorgängen auch wünschenswert ist). Wesentlich dabei ist, daß der im globalen Objektnamen explizit bezeichnete Geburtsknoten unabhängig vom Speicherungsort ist. Dies ermöglicht Ortstransparenz, da die physische Lokation eines Objektes wechseln kann (Migration von Objekten), ohne daß der globale Namen zu ändern ist. Auch werden Objekte stets an einem Knoten erzeugt, können aber über mehrere Knoten partitioniert oder repliziert gespeichert werden.
Durch die Hinzunahme des Geburtsknotens in globalen Objektnamen ergeben sich jedoch Probleme hinsichtlich der Gewährleistung von Verteilungstransparenz. Denn um auf extern erzeugte Objekte zugreifen zu können, ist die Spezifikation von Knotennamen erforderlich. Soll ein Anwendungsprogramm bzw. eine DB-Operation unverändert an mehreren Rechnern ausführbar sein, sind daneben sämtliche DB-Objekte vollständig zu spezifizieren, um eine korrekte Namensauflösung zu erreichen. Der üblicherweise verwendete Ansatz, um Programme und DB-Operationen ohne Spezifikation von Knotennamen erstellen zu können, liegt in der Definition sogenannter Synonyme (Alias-Namen). Diese werden vom DBS benutzerspezifisch verwaltet und gestatten die Abbildung von einfachen Objektnamen in vollqualifizierte globale Objektnamen. Die Knotenangaben befinden sich dabei lediglich in den Synonymtabellen des DBS, die typischerweise vom Datenbankadministrator für die lokalen Benutzer angelegt werden[16]. Synonyme werden u.a. in R* [Li81] und vielen kommerziellen Systemen (Tandem NonStop SQL [Ta89], DB2, Oracle etc.) verwendet.
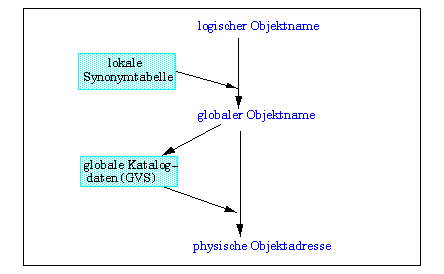
Die sich damit ergebenden Einzelschritte bei der Namensauflösung (name resolution) sind in Abb. 4-5 noch einmal zusammengefaßt. Zunächst erfolgt die Umsetzung logischer Namen in globale Objektnamen mit der im lokalen Katalog vorliegenden Synonymtabelle. Liegt kein Synonym vor, erfolgt die defaultmäßige Vervollständigung (Benutzername, Knotenname) zu einem globalen Namen. Der globale Objektname spezifiziert den Geburtsknoten, an dem auch die globale Verteilungsinformation für das betreffende Objekt vorliegt. Damit kann dann schließlich die physische Adresse (Speicherknoten) der zu referenzierenden Daten ermittelt werden.