Mehrrechner-Datenbanksysteme
Beim unkontrollierten Zugriff auf Datenobjekte im Mehrbenutzerbetrieb können eine Reihe von unerwünschten Phänomenen auftreten. Die wichtigsten dieser Anomalien sind verlorengegangene Änderungen ("lost update"), Lesen "schmutziger" Änderungen ("dirty read"), inkonsistente Analyse ("non-repeatable read") sowie sogenannte Phantome [Re87]. Änderungen können verlorengehen, wenn zwei Transaktionen parallel dasselbe Objekt ändern, wobei die zuerst vorgenommene Änderung durch die zweite Transaktion fälschlicherweise überschrieben wird. Das Lesen schmutziger Änderungen, welche von noch nicht zu Ende gekommenen Transaktionen stammen, führt zu fehlerhaften Ergebnissen, wenn die ändernde Transaktion noch zurückgesetzt werden muß und somit ihre Änderungen ungültig werden. Die inkonsistente Analyse sowie das Phantom-Problem betreffen Lesetransaktionen, die aufgrund parallel durchgeführter Änderungen während ihrer Ausführungszeit unterschiedliche DB-Zustände sehen.
Die genannten Anomalien werden vermieden durch Synchronisationsverfahren, welche das Korrektheitskriterium der Serialisierbarkeit erfüllen [EGLT76, BHG87]. Dieses Kriterium verlangt, daß das Ergebnis einer parallelen Transaktionsausführung äquivalent ist zu dem Ergebnis irgendeiner der seriellen Ausführungsreihenfolgen der beteiligten Transaktionen. Äquivalent bedeutet in diesem Zusammenhang, daß für jede der Transaktionen dieselbe Ausgabe wie in der seriellen Abarbeitungsreihenfolge abgeleitet wird und daß der gleiche DB-Endzustand erzeugt wird. Dies erfordert, daß eine Transaktion alle Änderungen der Transaktionen sieht, die vor ihr in der äquivalenten seriellen Ausführungsreihenfolge stehen, jedoch keine der in dieser Reihenfolge nach ihr kommenden Transaktionen. Die zur parallelen Transaktionsbearbeitung äquivalente serielle Ausführungsreihenfolge wird auch als Serialisierungsreihenfolge bezeichnet.
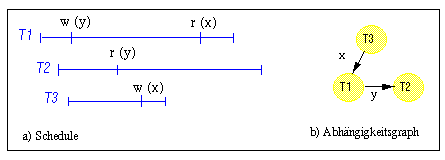
Um zu überprüfen, ob ein bestimmter Schedule, d.h. eine Ablauffolge von Transaktionen mit ihren zugehörigen Operationen, serialisierbar ist, kann ein Serialisierbarkeits- oder Abhängigkeitsgraph geführt werden. In diesem Graphen treten die einzelnen Transaktionen als Knoten auf und die Abhängigkeiten zwischen Transaktionen als (gerichtete) Kanten. Eine Abhängigkeit zwischen zwei Transaktionen Ti und Tj liegt vor, wenn Ti vor Tj auf dasselbe Objekt zugegriffen hat und die Operationen der beiden Transaktionen nicht reihenfolgeunabhängig (kommutativ) sind. Werden (wie üblich) als Operationen Lese- und Schreibzugriffe betrachtet, dann liegt eine Abhängigkeit vor, wenn wenigstens eine der beiden Operationen eine Schreiboperation darstellt. Es kann gezeigt werden, daß ein Schedule genau dann serialisierbar ist, wenn der zugehörige Abhängigkeitsgraph azyklisch ist. Denn nur in diesem Fall reflektiert der Graph eine partielle Ordnung zwischen den Transaktionen, die zu einer vollständigen Ordnung, die zugleich den äquivalenten seriellen Schedule bestimmt, erweitert werden kann.
Beispiel 8-1
Das Führen von Abhängigkeitsgraphen bietet jedoch keinen praktikablen Ansatz zur Implementierung eines Synchronisationsverfahrens, da hiermit meist erst nachträglich die Serialisierbarkeit von Schedules geprüft werden kann [Pe87]. Weiterhin wäre der Verwaltungsaufwand prohibitiv hoch, zumal auch Abhängigkeiten zu bereits beendeten Transaktionen zu berücksichtigen sind. Zur Synchronisation wird daher auf andere Verfahren zurückgegriffen, für welche nachgewiesen werden konnte, daß sie Serialisierbarkeit gewährleisten. Die Mehrzahl der vorgeschlagenen Verfahren läßt sich einer der drei folgenden Klassen zuordnen: Sperrverfahren, optimistische Protokolle sowie Zeitmarkenverfahren.
Diese Verfahrensklassen kommen auch für Verteilte Datenbanksysteme in Betracht. Als neue Anforderung ergibt sich hier, eine systemweite Serialisierbarkeit aller lokalen und globalen Transaktionen zu erzielen (globale Serialisierbarkeit). Hierzu reicht es nicht aus, nur die (lokale) Serialisierbarkeit in jedem Rechner zu gewährleisten, da in den einzelnen Rechnern unterschiedliche Serialisierungsreihenfolgen vorliegen können. Um eine hohe Leistungsfähigkeit zu erhalten, sollte diese Aufgabe wiederum mit möglichst geringem Kommunikationsaufwand erfüllt werden. Weiterhin sollte, wie bereits für zentralisierte DBS, die Synchronisation mit möglichst wenig Blockierungen und Rücksetzungen von Transaktionen erfolgen. Denn diese zur Behandlung von Synchronisationskonflikten verfügbaren Methoden haben beide einen negativen Einfluß auf Durchsatz und Antwortzeiten. Eine weitere Anforderung im verteilten Fall ist eine möglichst hohe Robustheit der Synchronisationsprotokolle gegenüber Fehlern (Rechnerausfall, Kommunikationsfehler). Erweiterungen werden daneben bei replizierten Datenbanken notwendig, um die wechselseitige Konsistenz von Replikaten sicherzustellen und Transaktionen mit aktuellen Objektkopien zu versorgen.
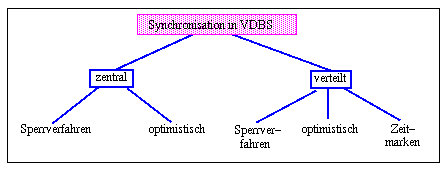
Da replizierte Datenbanken in Kap. 9 behandelt werden, konzentrieren wir uns hier zunächst auf die Synchronisation in partitionierten Datenbanken. Eine grobe Übersicht der hierbei in Betracht kommenden Verfahrensklassen ist in Abb. 8-2 gezeigt. Hierbei wird zwischen verteilten und zentralisierten Verfahren unterschieden, wobei letztere auf einem ausgezeichneten Knoten durchgeführt werden. Beide Alternativen bestehen für Sperrverfahren sowie optimistische Protokolle, während für Zeitmarkenverfahren nur eine verteilte Realisierung sinnvoll ist. Wie schon in zentralisierten DBS können die einzelnen Verfahrensklassen auch in Verteilten DBS vielfältig miteinander kombiniert werden (z.B. Sperrverfahren mit optimistischen Protokollen).