
Duration
Description
Scholarly entities like publications, their authors and their affiliations (originating institutions), and publication organs (conference venues or journals) are the focus of bibliometric analyses. These entities can be compared by the number of associated publications, and the impact may be estimated by the number of citations the associated publications receive.
Citation Analysis:
The impact of scientific publications is often estimated by the number of citations they receive, i.e. how frequently they are referenced by other publications. Since publications have associated authors, originating institutions and publication venues (e.g. journals, conference proceedings) citations have also been used to compare their scientific impact. The tremendous scope of new scientific archives like Google Scholar makes it possible to freely access citation data for millions of publications and authors and thus to evaluate the citations for entire conferences and journals.
We performed offline, data-warehouse-based citation analysis for selected database conferences (VLDB, SIGMOD) and journals (TODS, VLDB Journal, SIGMOD Record) in August 2005 and in 2007. The citation/reference counts for the 10 years of 1994-2003 were determined by combining data from DBLP, ACM Digital Library, and Google Scholar (GS) as described in our iFuice paper. All reference counts are from Google Scholar and ACM. Reference counts from GS have problems, e.g. they include self-citations and pointers from web pages. We also noticed cases where GS grouped together different versions of the papers, book reviews and books, or had serveral entries of the same publications. We therefore applied some post-processing to deal with such cases. Still GS is by far the most current and comprehensive source at this time and we find the results quite interesting and helpful to uncover certain trends.
The analysis results were published in SIGMOD Record 2005. In 2007 we reran the analysis for an extended period of 12 years (1994-2005); a short summary of the new results is in a APE08 paper (slides).
We developed the Online Citation Service (OCS), a new system for online citation analysis of computer science research. For any set of DBLP publications, it retrieves and integrates citation data on demand from four different data sources: Google Scholar, Microsoft Libra, ACM Digital Library, and Citeseer. A set of search query generators is provided to efficiently retrieve relevant citation data and to iteratively refine search results for improved data quality.
We recently introduced a new tool - the CitedReferencesExplorer ( CRExplorer ) – which can be used to disambiguate and analyze the cited references (CRs) of a publication set downloaded from the Web of Science (WoS) or Scopus. The tool is especially suitable to identify those publications which have been frequently cited by the researchers in a field and thereby to study for example the historical roots of a research field or topic. CRExplorer simplifies the identification of key publications by enabling the user to work with both a graph for identifying most frequently cited reference publication years (RPYs) and the list of references for the RPYs which have been most frequently cited.
Affiliation Analysis:
Bibliometric studies of computer science and database publications to date mainly focus on the number of papers and citations per author or per journal. As (commercial) bibliographic systems concentrate on journals, there is only little analysis regarding the affiliations of authors in computer science and database research.
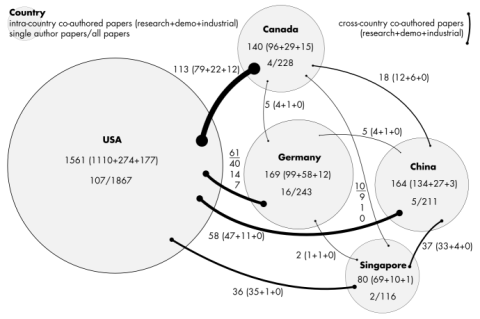
We analyze author affiliations of publications to determine the main institutions contributing research to a specific field. For instance, we determine top affiliations in terms of number of papers (productivity) and also aggregate the numbers at varying level of detail, e.g. cities, countries, and continents.
Author affiliations in publications are given in quite heterogeneous form. Before any analyses on these data can be undertaken, the affiliation mentions denoting the same real world institutions have to be aligned. For this, we investigated into web-based affiliation recognition, matching, and clustering (cf. our publications).
Interpreting multiple-author papers as collaborations, bonds within and across institutions, cities, countries, and continents become visible (e.g. see illustration).
Prototypes:
- CRExplorer
- OCS (DBLP publication lists for one author or for one venue can be analyzed by acquiring citation counts from Google Scholar)
- Google Scholar H-Index calculates the single publication h index (and further metrics) based on Google Scholar
- Affiliation browser
Dataset example:
With the following archive we provide some of our data for download – contained therein:
- affiliation strings, mostly as available from ACM, though in cases also the original PDFs were taken into account
- correspondences between affiliation strings on institution level, i.e. neglecting departments etc.
Download: affiliationstrings.zip
Note: Other object matching datasets (incl. publication data) is available via Benchmark datasets for entity resolution.