
Duration
Description
On this page we present Caravela, a semantic web content management system that offers dynamic information integration and semi-automatic categorization. Content and documents of different types can be integrated from diverse semi-structured sources and categorized along multiple dimensions creating a faceted classification. We offer the following features to reduce the manual work posed onto the community in maintaining a structured content portal.
- Dynamic information integration from attached data sources, e.g. Wikipedia for any type of content and Google Scholar in the publication domain.
- Automatic cross-linking provides dynamic categorizations at no user cost.
- Semi-automatic categorization along multiple taxonomies.
- Emerging tag clouds of attribute values enhance navigation.
Caravela currently is actively used to categorize scientific research publications, creating online bibliographies, e.g. on schema evolution, data cleaning, and others. Publication data can be entered by:
- Supplying search keywords – the user can choose to integrate publications as found by Google Scholar using these keywords
- Uploading a PDF file – PDFMeat tries to find the according metadata
- Editing manually – also for curation of automatically added entries
For entries without attached PDF file a one-click or batch solution is available to search and attach the according file as found on the web. Thus, both the metadata–data as well as data–metadata mapping can be established.
System overview:
Caravela provides functionalities for automating content integration from the Web, content transformation, and semi-automatic categorization. To help maintain high quality content and categorizations all information-editing tasks can also be performed manually.
Each document in Caravela, e.g. publication or movie, is associated to a particular content type and described by several attributes. For example, the publication content type typically has attributes like title, authors, year, and venue. Attributes either store data in simple data types or comprise whole lists of constituents, e.g. a list of authors.
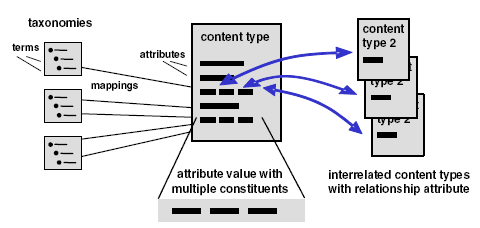
Web data integration:
The ‘create from web’ interface allows effortless acquisition of new content by retrieving attribute values from the web. Users choose an attached service and enter e.g. a keyword to search for content using that service. The returned results are displayed in a wiki-like format to allow editing and altering the returned details before adding to the document collection.
An ad-hoc and light-weight schema matching takes place to map the available attributes of the external data source to the internal attributes of the according content type. As the schemas of content types usually consist only of few attributes, we use simple name-based matching using string matchers. To supply mappings that cannot be determined automatically the user can provide synonyms manually that get merged with the auto-generated mapping.

Automatic cross-linking:
Automatic cross-linking on co-occurring terms across content instances with giving occurrence counts. As new instances are added the attribute values instantaneously get cross-linked to pages showing all instances sharing the same value. The occurrence count is displayed dynamically behind each attribute value or constituent.

Emerging tag clouds:
Attribute values or its constituents can be rendered as weighted list. Here the occurrence counts (or other attribute values, e.g. citation counts) get represented by font size or shades of gray (or a combination thereof). Thus, more frequent terms get represented larger or in a darker/deeper colour.
Such tag clouds are great means to start browsing a collection, as each attribute value or constituent links to appropriate overview pages. No user effort in creating them.
Categorizing along multiple taxonomies:
Content instances in Caravela may be categorized along multiple taxonomies. Offering multiple hierarchies instead of merely one, each taxonomy may be more clearly defined and thus smaller in size, i.e. more easily to understand and maintain.
Semi-automatic categorization:
One approach for semi-automatic categorization is achieved by deriving taxonomy correspondences from given attribute values or parts thereof as specified via a regular expression pattern. Existing attribute values can be used to create a new taxonomy from scratch, establishing according correspondences to the content instances. This is useful when there are many terms in attributes that are to form a category and/or no other sources available. From a flat taxonomy of single years e.g., we can derive a first level of more general terms by constructing the decades. Another level on top of that would be presented by the according centuries. These functionalities can be extended in Caravela by providing scripts that contain functions to return a more general term to a given term.
Drag'n'drop categorization:
To ease manual categorization and thus maintain high quality of categorization a drag’n’drop interface is was developed.
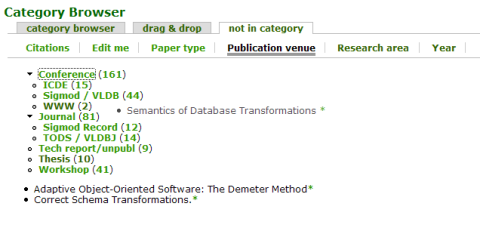
Download:
Caravela is built on Drupal. We publish our modules for general use for a growing user base.
- Create from web includes operators e.g. for Wikipedia, ISBNdb, Google Scholar
- Citation counts periodically update via google scholar)
- Scholarly utilties to retrieve pdf and abstracts via google search and from acm.org; normalizing concatenated author lists (variants to consistent Surname, Forname; Sur…); split/join authors from/to concatenated/multiple field
- Drag’n’drop categorization (outdated – anybody?)
- OAI2 for CCK (found new maintainer, thanks!)
A new operator for ‘Create from web’ to retrieve scholarly metadata by merely supplying a PDF file is going to be incorporated, see pdfmeat; supplying a URL works via GScholar service.
The CCK content type definition (cck: import) used for publications is attached below.
Future enhancements:
To offer better automatic categorization the existing document instances can be compared with the ones to be inserted. It could be argued, e.g., that publications by the same authors cover the same research area, thus the categorizer could suggest the same category item for newly added publications. Thus, upon entering title (and abstract) to new publications these bits of information can be used to calculate similarities to other existing publications to derive some category suggestions. In the movie domain, category suggestions could be derived e.g. upon same director or overlapping actors.
| Attachment | Size |
|---|---|
| cck_nodetype_pub.txt | 11.77 KB |
Publikationen (3)
| Dateien | Cover | Beschreibung | Jahr |
|---|---|---|---|

|
Aumüller, D.
BTW 2009
|
2009 / 3 | |

|
Aumüller, D.
; Rahm, E.
E. Franconi, M. Kifer, and W. May (Eds.): ESWC 2007, LNCS 4519, pp. 729–738, 2007
|
2007 / 6 | |

|
2006 |