Duration
Description
SemRep (Semantic Repository) is a multi-lingual, graph-based platform integrating different knowledge resources about concepts and their semantic relations. SemRep focuses on concepts and their relations rather than on instance (entity) data as in most other knowledge bases, such as DBpedia, Freebase, or Geonames. It supports six general semantic relation types between concepts (equal, is-a, inverse is-a, has-a, part-of and related) and a confidence measure indicating the likelihood that two concepts in SemRep are related. Currently SemRep combines the resources WordNet (English Language), OpenThesaurus (German Language) and the UMLS Metathesaurus (biomedical domain). Additionally, it contains some millions of automatically extracted semantic relations from the English Wikipedia and selected relations from ConceptNet. This makes SemRep a powerful resource for data integration tasks depending on background knowledge. for example for findig semantic correspondneces between schemas and ontologies or sematically enriching simple mappings. The following table fives an overview about the integrated resources and their number of concepts and relations. Altogetherm SemRep contains more than a million concepts and 5 million relations.
| Resource | Language | Domain | Number of Concepts | Number of Relations |
|---|---|---|---|---|
| WordNet | English | General Purpose | 119,895 | 1,881,346 |
| Wikipedia | English | General Purpose | 548,685 | 1,489,577 |
| Wikipedia Redirects | English | General Purpose | 296,279 | 676,083 |
| UMLS | English | Medical Domain | 938,527 | 1,265,703 |
| OpenThesaurus | German | General Purpose | 58,472 | 614,559 |
| ConceptNet (excerpt) | English | General Purpose | 90,364 | 245,320 |
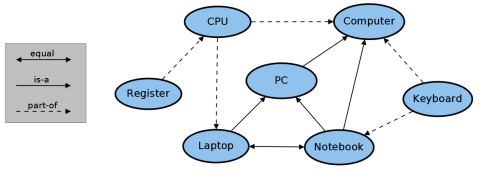
As shown in the illustration below, SemRep is implemented as a knowledge graph with the nodes being the concepts and the edges being the semantic concept relations. However, SemRep also contains a query engine to either lookup or derive the semantic relation type between two given concepts (terms) A and B. SemRep can quickly determine the relation type holding between the two elements. If there is no direct relation SemRep uses different techniques to still find a relation, e.g. by combining several relatiojs and zheir types along a path in the graph (up to a maximal distance of 4). In the shown example, SemRep is able to indirectly derive relations such as (register, part-of, notebook). Details about the used approaches can be found in the SemRep paper below. The reasoning facilities of SemRep make it more powerful than previous background knowledge repositories like WordNet.
SemRep is fully configurable and can be extended by further resources. Rsource files to be imported are simply sets of triples of the form (word1, word2, relation type).
Download
We offer SemRep for download for non-commercial use, i.e. for reaerch and education purposes. Additionally, we offer the lexicographic resources that are used by SemRep. These resources are independent from SemRep. There are two forms how to use SemRep:
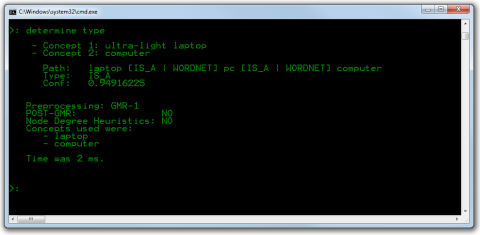
- Use a console-based interface to manually import resources, determiny relation types or explore the repository graph. Fig. 2 shows how SemRep can be used to determine an is-a relation between the concepts ultra-light laptop and computer.
- Use an API (Java library) to integrate SemRep in a software project. Currently, no source code is offered and we can only provide limited support. There is a user's guide in the help directory of the SemRep directory explaining the basics of using the console-based interface or the API.