
Duration
Description
Overview:
Automatically matching entities (objects) and ontologies are key technologies to semantically integrate heterogeneous data. These match techniques are needed to identify equivalent data objects (duplicates) or semantically equivalent metadata elements (ontology concepts, schema attributes). The proposed techniques demand very high resources that limit their applicability to large-scale (Big Data) problems unless a powerful cloud infrastructure can be utilized. This is because the (fuzzy) match approaches basically have a quadratic complexity to compare the all elements to be matched with each other. For sufficient match quality, multiple match algorithms need to be applied and combined within so-called match workflows adding further resource requirements as well as a significant optimization problem to select matchers and configure their combination.
Goals:
- Efficient parallel execution of match workflows in the cloud
- Efficient application of machine learning models for entity/ontology matching
General Entity Matching Workflow:
The common approach to improve efficiency is to reduce the search space by adopting blocking techniques. They utilize a blocking key on the values of one or several entity attributes to partition the input data into multiple partitions (called blocks) and restrict the subsequent matching to entities of the same block. For example, product entities may be partitioned by manufacturer values such that only products of the same manufacturer are evaluated to find matching entity pairs.
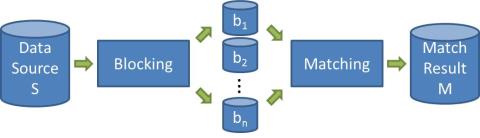
Entity Matching with MapReduce:
The MapReduce model is well suited to execute blocking-based entity matching in parallel within several map and reduce tasks. In particular, several map tasks can read the input entities in parallel and redistribute them among several reduce tasks based on the blocking key. This guarantees that all entities of the same block are assigned to the same reduce task so that different blocks can be matched in parallel by multiple reduce tasks.
Skew Handling / Load Balancing: Basic MR implementation of entity matching is susceptible to severe load imbalances due to skewed blocks sizes since the match work of entire blocks is assigned to a single reduce task. We are developing effective load balancing approaches to data skew handling for MR-based entity matching (and, in general, all kind of pairwise similarity computation). For a quick overview see our CIKM 2011 poster (right).
Redundancy-free comparisons: Modern entity matching approaches assign entities to more than one block. For example, multi-pass approaches use several blocking keys to still achieve high recall in the presence of noisy data. Similarily, token-based matching approaches (e.g., PPJoin) generate a list of tokens (i.e., blocks) for each entity. Such overlapping blocks may lead to mutliple comparisons of the same pair of entity which in turn decreases efficieny. We therefore develop redundancy-free approaches that ensure that every entity pair is processed by one reduce task only.

Dedoop:
We summarized our latest research results in a prototype, called Dedoop (Deduplication with Hadoop). It is a powerful and easy-to-use tool for MapReduce-based entity resolution of large datasets.
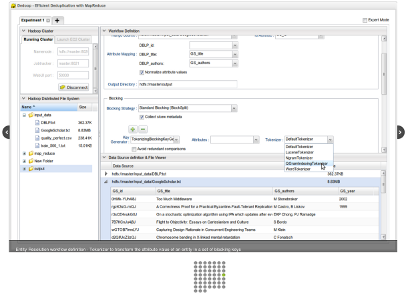




Dedoop…
- Provides a Web interface to specify entity resolution strategies for match tasks
- Automatically transforms the specification into an executable MapReduce workflow and manages its submission and execution on Hadoop clusters
- Is designed to serve multiple users that may simultaneously execute multiple workflows on the same or different Hadoop clusters
- Provides load balancing strategies to evenly utilize all nodes of the cluster
- Includes a graphical HDFS and S3 file manager
- Supports the repeated execution of jobs within a MapReduce workflow until a stop condition if fulfilled
- Automatically spawns and terminates SOCKS proxy servers to pass connections to Hadoop nodes on Amazon EC2
- Supports to configure and launch new Hadoop clusters on Amazon EC2
- Can be adapted to configure, schedule, and monitor arbitrary MapReduce workflows
Project members
Funding / Cooperation
Publikationen (22)
| Dateien | Cover | Beschreibung | Jahr |
|---|---|---|---|

|
2012 / 4 | ||

|
2012 / 2 | ||

|
2011 / 11 | ||

|
2011 / 10 | ||

|
Kolb, L.
; Köpcke, H.
; Thor, A.
; Rahm, E.
Proc. 3rd Intl. Workshop on Cloud Data Management (CloudDB), 2011
|
2011 / 10 | |

|
Groß, A.
; Hartung, M.
; Kirsten, T.
; Rahm, E.
2nd International Conference on Biomedical Ontology (ICBO 2011)
|
2011 / 7 | |

|
2011 / 3 | ||

|
Rahm, E.
Schema Matching and Mapping, Springer-Verlag
|
2011 / 2 | |

|
Köpcke, H.
; Thor, A.
; Rahm, E.
Proc. 36th Intl. Conference on Very Large Databases (VLDB) / Proceedings of the VLDB Endowment 3(1), 2010
|
2010 / 9 | |

|
Kirsten, T.
; Kolb, L.
; Hartung, M.
; Groß, A.
; Köpcke, H.
; Rahm, E.
Proc. 8th Intl. Workshop on Quality in Databases (QDB), 2010
|
2010 / 9 |